fetching data ... 
Background: Occupational data about patients holds the potential for enhancing diagnostic accuracy, refining treatment strategies, and informing the development of targeted policies and interventions in healthcare. Despite its importance, the inclusion of this Social Determinant of Health (SDOH) in healthcare research and practice is often overshadowed by other SDOHs, and its recording in the electronic medical record (EHR) compromised and relegated to unstructured fields. In the field of rheumatology, this SDOH becomes more important because of prevention and intervention policies to reduce disability (including sick leave) associated with these pathologies. To retrieve, structure and use the information from this SDOH, as well as to characterize which factors influence its collection, deep learning and text mining algorithms can be used.
Objectives: The objective of this study is two-fold: 1. to assess the performance of named entity recognition models based on transformers when extracting occupation mentions in real-world rheumatology clinical notes. 2. to describe the demographic and clinical characteristics that influence the collection of occupation-related information in a rheumatology outpatient setting.
Methods: Transformer-based deep learning models (i.e., RoBERTa) for occupation recognition were trained on Spanish clinical texts using public corpora. A gold standard (GS) dataset was constructed using a random selection of 2,000 first-visit clinical notes from the rheumatology service at Hospital Clínico San Carlos, Madrid, Spain, spanning from 2007 to 2017 (HCSC-MSKC cohort). Occupation mentions were annotated by two researchers, the rate of agreement between them calculated and discrepancies resolved through consensus. The performance of the models was measured using the F1-score metric. Once assessed, predictions were made to identify occupation mentions in the rest of the clinical notes of the HCSC-MSKC cohort. Afterwards, to study the factors influencing the collection of this SDOH, the following inclusion criteria were defined to reduce selection bias: patients who had a written report at the first visit, were in active employment status and were under 65 years of age were included. Besides, a 1:1 matching was done, using k-nearest neighbors, to select controls (i.e., subjects with no occupation mention) by age, sex, number of visits, time elapsed since first visit and calendar year. Bivariate analyses were conducted for variable selection, including diagnoses and quality of life measures. Those with a p-value < 0.15 were further included in the multivariate analyses. These were conducted in a stepwise fashion until all included variables had a p-value < 0.05.
Results: The GS inter-annotator agreement was 0.67 and the F1-score 0.73. Only 8% of the GS notes had at least one occupation mention. Predictions were made on 117,068 clinical notes belonging to 35,470 patients. After applying the inclusion criteria, 3,527 patients had at least one valid occupation mention identified by the models. The spectrum of identified professions exhibited considerable diversity (e.g., naturopath, cabinetmaker, railway worker). After matching and selecting variables, the multivariate analyses were conducted. Image 1 shows the results.
Multivariate analyses results
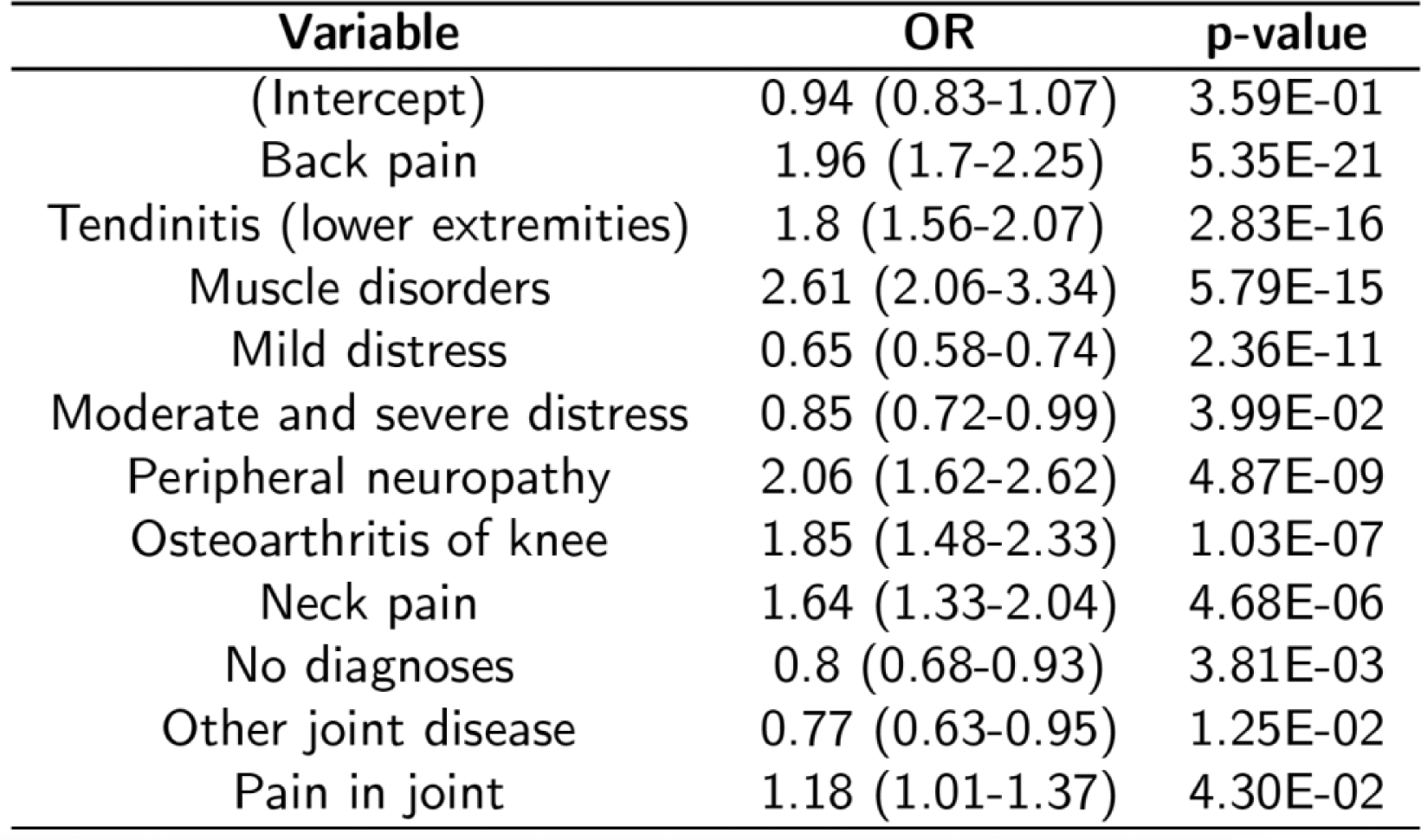
Conclusion: We have validated a deep learning model, based on large pre-trained language models (i.e., RoBERTa), in real-life clinical notes, able to identify occupation mentions. Only 10% of patients had at least one occupation mention, which could have negative implications for care decision making. Diagnoses related to highly disabling mechanical pathology (i.e., back pain, muscle disorders) were associated with a higher probability of occupation collection. Automatically retrieving occupational data from extensive collections of notes could hold great potential for longitudinal research. However, this SDOH should be encouraged to be collected on a more regular basis.
REFERENCES: NIL.
Acknowledgements: NIL.
Disclosure of Interests: None declared.