fetching data ... 
Background: The arrival of artificial intelligence (AI) in medicine promises to revolutionize the delivery of healthcare services.
Objectives: To evaluate the feasibility of using Chat-GPT, an AI tool, compared to expert rheumatologists in the context of e-consultations (electronic consultations via the internet) made by primary care physicians.
Methods: A comparative cross-sectional study was conducted in which responses to primary care e-consultations provided by Chat-GPT 4.0 and specialist rheumatologists were analyzed. Three expert rheumatologists (JLAS, AGV, JQD) with over 100 years of combined experience assessed the responses in terms of scientific accuracy, clinical relevance, and clarity. Five primary care physicians (NCV, CCP, JDQ, ISV, NPR) with more than 125 years of combined experience evaluated the responses in terms of user satisfaction. Scales from 1 to 5 were used, with 1 being the worst rating and 5 the best. The differences in the paired means were analyzed, and the weighted kappa index was calculated to measure the agreement among evaluators.
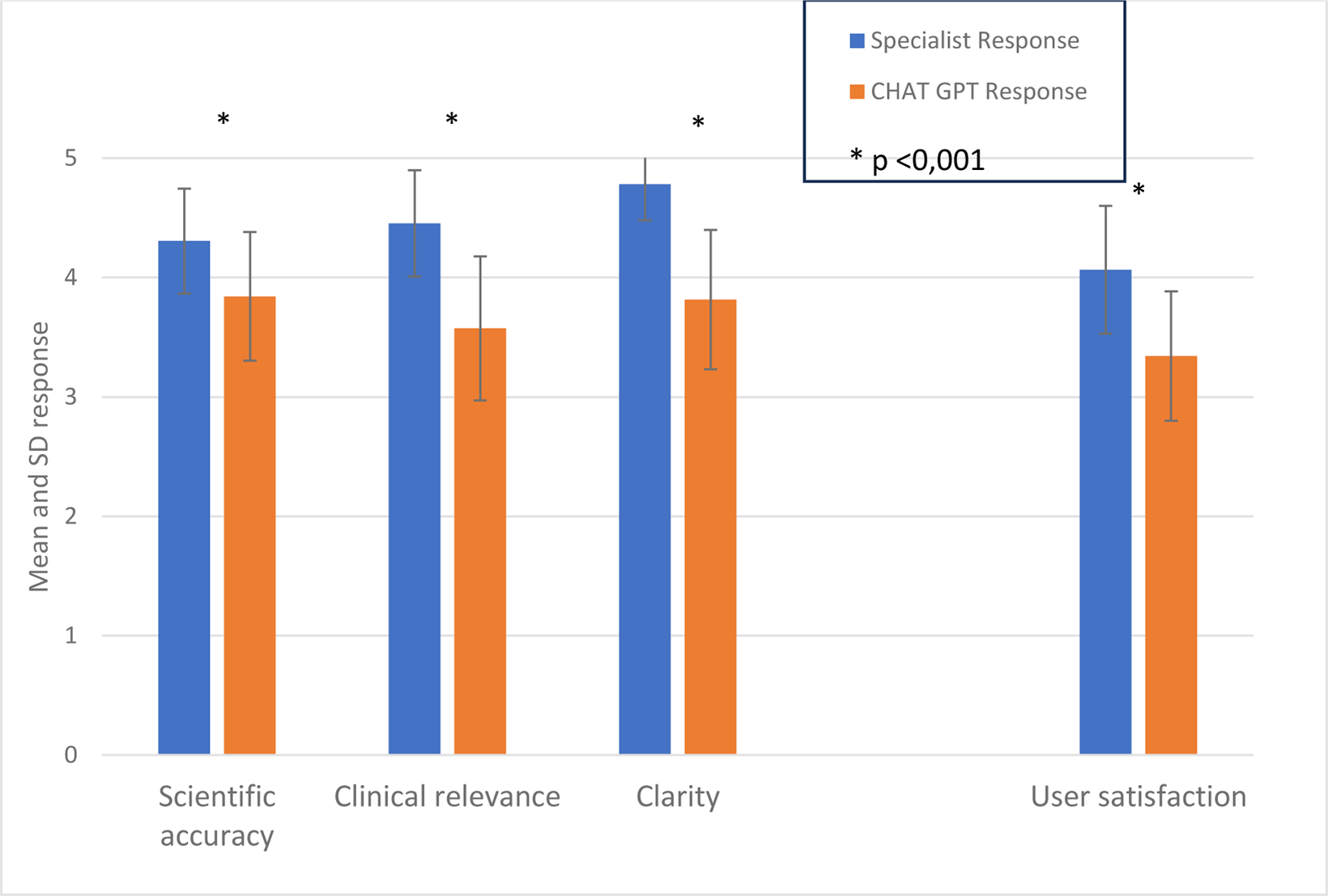
Results: Out of the total 85 e-consultations that took place during the study period, a total of 72 were included. The 13 e-consultations removed from the analysis were excluded due to lacking analyzable medical content, being of an administrative or logistical nature. The concordance among expert rheumatologists was poor (Kappa 0.011-0.308) and slightly better (although still poor) among family doctors (Kappa 0.328-0.359) (indicating variability in the interpretation of clinical data). Significant differences were observed in all categories. The specialists’ responses obtained high averages (Science: 4.31; Relevance: 4.45; Clarity: 4.78; Satisfaction: 4.06) with a smaller standard deviation, reflecting a consistency in the highly rated responses. On the other hand, Chat-GPT_4.0 showed a slightly lower performance (Science: 3.84; Relevance: 3.57; Clarity: 3.81; Satisfaction: 3.34), with greater variability in the responses. The paired differences were statistically significant (p<0.001) for all categories (Figure 1).
Conclusion: While Chat-GPT proves to be a promising tool for support in e-consultations for rheumatology, the findings underscore that it does not replace the expertise and clinical knowledge of rheumatologists. The use of Chat-GPT could be considered complementary, focused on areas with limited access to specialists.
REFERENCES: NIL.
Mean and Sd of the evaluated variables.
Acknowledgements: NIL.
Disclosure of Interests: Ramón Mazzucchelli From Roche, Pfizer, and others. Not for this study., Paula Turrado-Crespí: None declared, Natalia Crespí-Villarías: None declared, José Luis Andréu Sánchez: None declared, Julia Dorado: None declared, Jesús A. García-Vadillo: None declared, Cristina Carvajal: None declared, JAVIER QUIROS DONATE: None declared, Inmaculada Sanchez: None declared, Nuria Puyo: None declared, Raquel Almodóvar: None declared, Pedro Zarco-Montejo: None declared, Cristina Pijoán-Moratalla: None declared, Elia Pérez-Fernández: None declared.