fetching data ... 
Background: Systemic lupus erythematosus is a rare multisystemic disease that often requires lifelong treatment and affects various aspects of life. Patient education is an essential pillar of disease management but is often impaired by physician’s lack of time and staff. To provide high quality patient information, the initiative Lupus100.org was launched[1]. Here, lupus experts and Lupus Europe listed and answered the 100 most important questions on lupus. The creation of such information collections needs a lot of time and resources. With the wide availability of large language models (LLM) such as ChatGPT, the question arises to what extent they could support physicians in the care of patients.
Objectives: To assess the capability of the LLM ChatGPT-4 vs. physician-generated responses to answer the 100 most frequently asked patient questions related to lupus.
Methods: ChatGPT-4 responses were generated by entering the English questions from
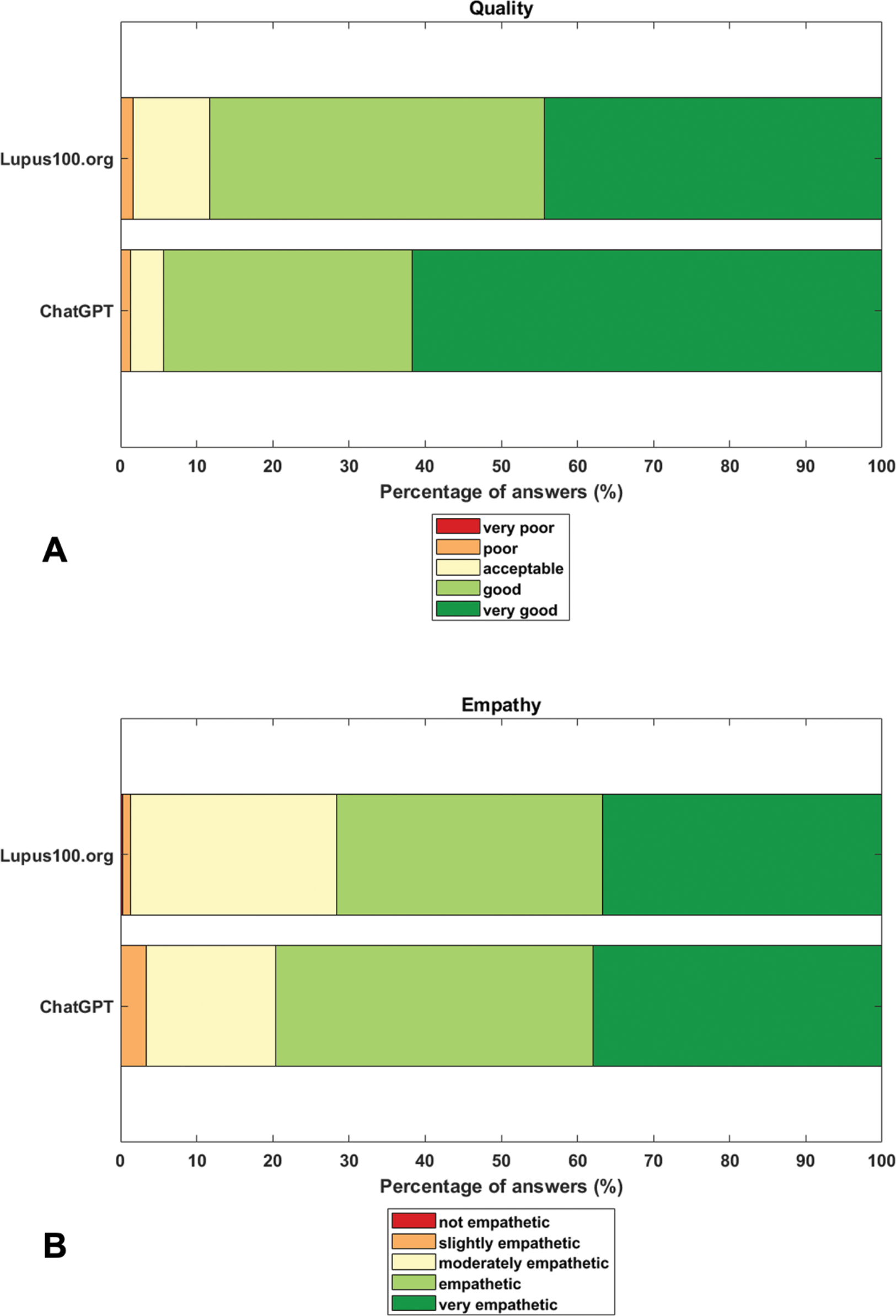
Results: Across the 100 questions, evaluators scored the mean quality of ChatGPT-4 significantly higher than that of Lupus100.org (t = 4.25; p = 0.001) (Table 1). Empathy ratings were comparable between both sources (t = 1.14; p = 0.26). Very few answers were rated as of poor quality or empathy (Figure 1). The preferred response was significantly more likely to come from ChatGPT-4 (57% vs. 43%; χ 2 = 5.88, p = 0.02).
Mean (SD) word count of replies was significantly lower for Lupus100.org than for ChatGPT-4 (241 [135] vs. 372 [52]; t = 9.08; p = 0.001). Word count was positively correlated with quality and empathy in Lupus100.org (r = 0.52; p = 0.001 and r = 0.34; p = 0.001). If only answers longer than median word count by Lupus100.org were analyzed, evaluators rated the two sources as equivalent in terms of quality (t = 0.65; p = 0.51) and Lupus100.org significantly better in terms of empathy (t = -2.17; p = 0.03).
Conclusion: In this study, ChatGPT-4 was able to generate responses with high quality and empathy to patient questions concerning lupus. The length of the response seems to influence these parameters and can be produced faster by LLM, while physicians can probably optimize empathy by a thorough edit of answers. Collaboration between LLM and physicians has the potential to improve the availability of high quality and empathic patient information in times of physician shortage.
REFERENCES: [1] Lupus100.org [Internet]. [cited 2023 Dec 27]. Available from:
Comparison of ChatGPT-4 and Lupus100.org in terms of quality and empathy
| ChatGPT-4 | Lupus100.org | |||
|---|---|---|---|---|
| mean (SD ) | mean (SD ) | p-value | Effect size [95% CI] | |
| Complete set of 100 questions | ||||
| Quality score | 4.55 (0.65) | 4.31 (0.72) | 0.001 | 0.35 [0.17 – 0.51] |
| Empathy score | 4.14 (0.82) | 4.07 (0.84) | 0.27 | 0.09 [0.07 – 0.25] |
| questions with Lupus100.org answer length > median | ||||
| Quality score | 4.51 (0.69) | 4.46 (0.72) | 0.51 | 0.08 [-0.15 – 0.30] |
| Empathy score | 4.09 (0.82) | 4.29 (0.77) | 0.03 | -0.25 [-0.48 – -0.02] |
Acknowledgements: NIL.
Disclosure of Interests: Isabell Haase Abbvie, AstraZeneca, Boehringer Ingelheim, Galapagos, GSK, Janssen, Lilly, Medac, Novartis, UCB, AbbVie, Boehringer Ingelheim, Medan, AbbVie, Celgene, Chugai, Hexal, Janssen, Medac, UCB, Tingting Xiong: None declared, Antonia Rissmann: None declared, Johannes Knitza: None declared, Julia Greenfield: None declared, Martin Krusche Novartis, Abbvie, Lilly, Galapagos, Pfizer, Medac, GSK, Novartis, Roche, Abbvie, Lilly, Galapagos, Pfizer, Medac, Novartis, Sobi, Sanofi.