fetching data ... 
Background: The role of Artificial Intelligence (AI) and large language modules (LLMs) in medicine is becoming more precise with every passing day1. AI-generated scientific abstracts have been deemed comparable to content created by humans2. Less is known on the capabilities of LLM in accurately assessing outcome measures for rheumatic diseases.
Objectives: We aimed to use AI to assess the severity of disease in idiopathic inflammatory myopathies (IIM) through automated scoring of Myositis Disease Activity Assessment Tool-Visual Analogue Scale (MDAAT-VAS) and compare such AI-based assessments with those conducted by human evaluators as this may have commercial utility in trial recruitment.
For our study, we used the open-access LLM, Claude (ver.2, Anthropic, USA), and embedded a document denoting the Myositis Disease Activity Assessment Tool for Visual Analogue Scale (MDAAT-VAS), depicting instructions for scoring, along with 30 fictitious cases of IIM curated by multiple clinicians based on previous clinical experience (Supplementary material 1).
Methods: Claude was asked to score a VAS score for each of the 9 organ systems mentioned in the MDAAT score (Constitutional, Cutaneous, Skeletal, Gastrointestinal, Pulmonary, Cardiovascular, Muscular, Extramuscular, Global), independently, using the following prompt: “Please only score MDAAT-VAS, autonomously, based on how detrimental those involvements are for everyday life and workability, considering that VAS 10 = almost death. Consider polyarthritis among as a skeletal involvement and dysphagia as a gastrointestinal involvement”. Three independent readers, two experienced in IIM research (> 3 years), also scored the MDAAT-VAS for each of these 30 IIM cases. Individual and average Intraclass Correlation Coefficient (ICC) with a two-way random effects model and Pearson’s correlation coefficient were calculated to check the inter-reader variability between Claude and each assessor on Stata 18.
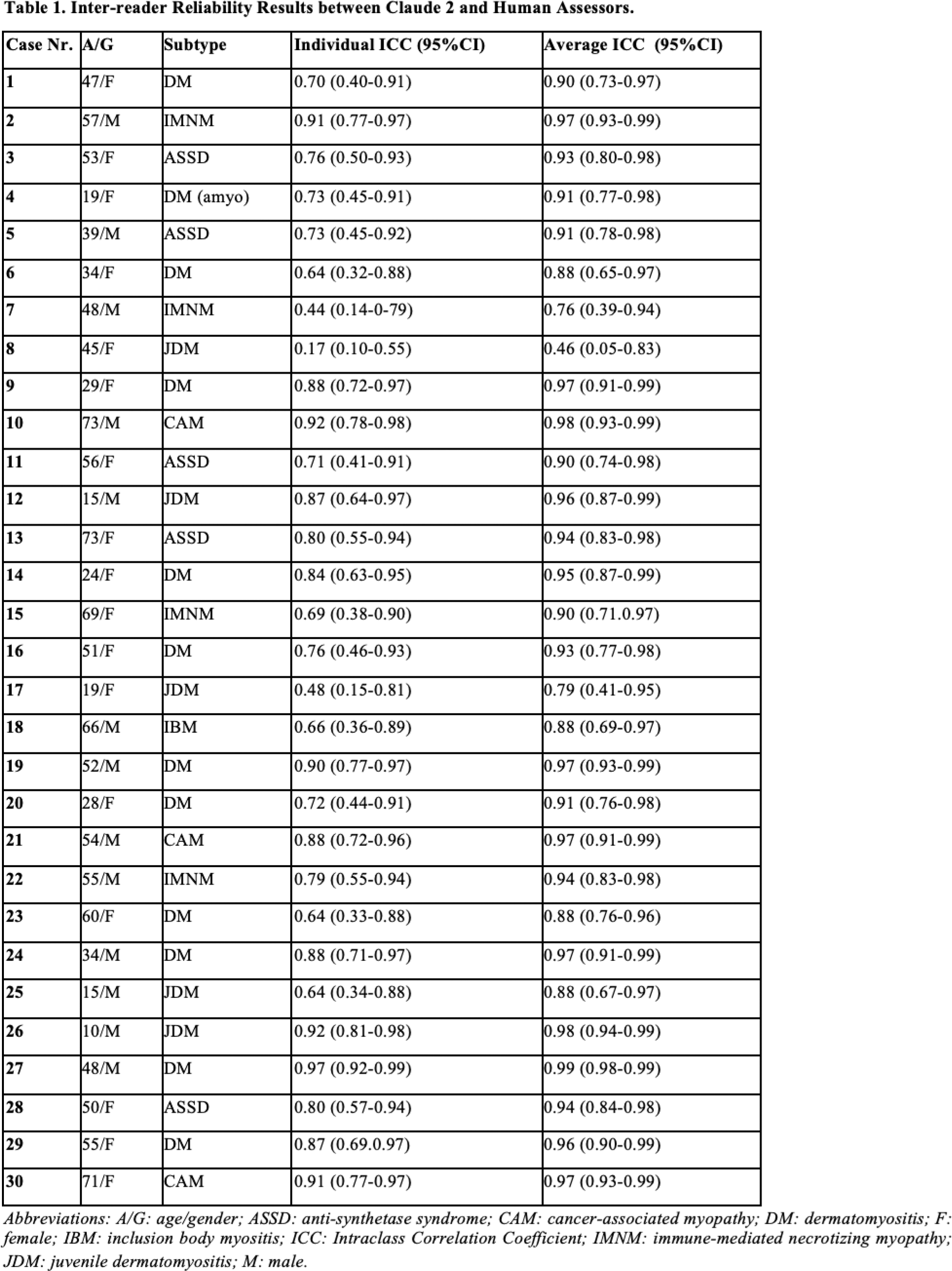
Results: Thirty training cases and the MDAAT-VAS scores given by Claude and assessors were analyzed. Considering each MDAAT-VAS as a separate rating, individual and average ICC were 0.77 (95%CI: 0.73-0.81) and 0.93 (95%CI: 0.92-0.94), respectively (n.270 targets, n.4 raters). In 29 out 30 cases (97%), the average ICC was > 0.75, demonstrating good reliability between human assessors and Claude.
Table 1 presents the detailed inter-reader reliability results between Claude and the three independent assessors, showcasing the individual and average ICC for each case. In the context of this study, Claude’s assessments demonstrated significant reliability with human evaluators.
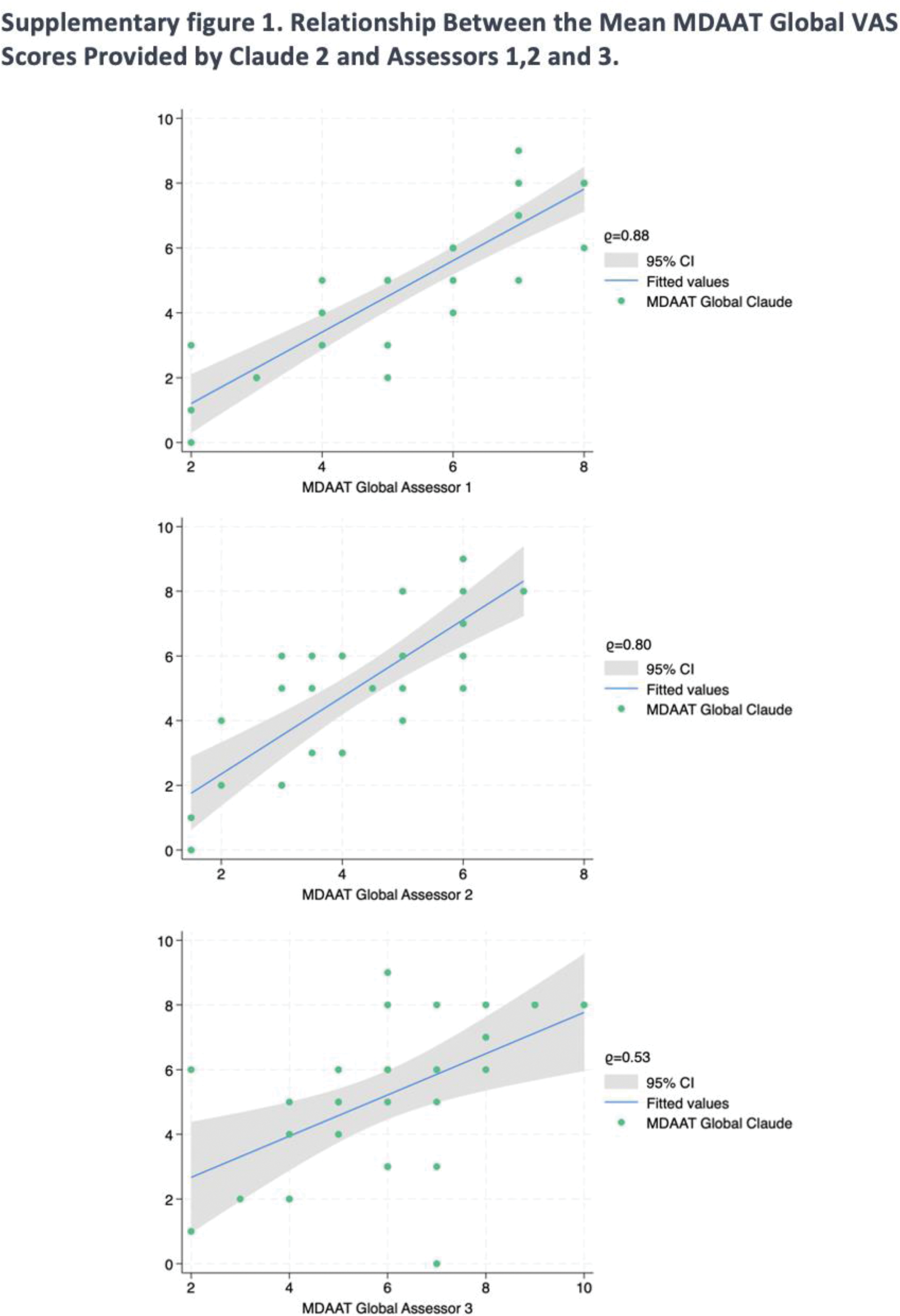
Pearson’s correlation coefficients for the “Global assessment” score highlighted a strong positive correlation between the mean MDAAT Global VAS scores provided by Claude-2 and those by expert assessor 1 (r = 0.88, p < 0.001) and 2 (r = 0.80, p < 0.001). In contrast, a moderate positive correlation was observed with less experienced assessor 3 (r = 0.53, p = 0.002).
Conclusion: This study serves as a stepping stone in understanding the role of LLM in clinical application, particularly in the field of myositis. Claude 2 has demonstrated excellent consistency with human scoring in clinical cases of patients suffering from IIM. Its potential future uses are broad, ranging from clinical training for MDAAT scoring to the creation of clinical cases for use in trial recruitment by screening electronic records. As we continue to explore and harness the capabilities of LLMs, it is imperative to maintain a balance between technological advancement and the irreplaceable value of human clinical judgment without demonizing AI’s assistance.
REFERENCES: [1]
Acknowledgements: NIL.
Disclosure of Interests: None declared.