fetching data ... 
Background: Artificial intelligence (AI) has shown great promise to transform medicine and aid physicians with the diagnosis, treatment and monitoring of patients. A plethora of machine learning models are approved by the FDA to perform certain tasks. Most of them are built through a supervised learning approach using clinical datasets as input (images±clinical data) and a clinical decision as output, e.g. the detection of a rheumatic lesion on a radiograph. After the training phase, the machine learning model automatically detects the rheumatic lesions in patient images. One of the barriers to the adoption of AI in clinical care is the lack of transparency and trust in the AI decisions and the efficacy of these machine learning models. The most powerful black-box statistical models cannot be inspected to explain the decision-making process that led to the presented outcomes. New research areas emerged to develop additional methods that tackle these challenges. eXplainable AI (XAI) methods aim “to open up the black box”. Numerous types of XAI methods have been developed and applied to explain medical image analysis AI models [1]. Imaging-based AI models have been applied to aid rheumatologists with various diagnostic tasks and XAI methods are readily applied to enhance the trust in the presented AI models. Saliency or heat maps are the most commonly used XAI method on images. Ground truth does not exist for saliency maps, so assessing their quality relies on human interpretation [2]. Previous work casted doubts on the ability of XAI methods to explain how AI models arrived at their decision [3], and whether even humans can explain their own decisions properly [4].
Objectives: To study to what extent saliency maps can be trusted to explain black box image analysis models in rheumatic diseases (and beyond) and analyze the role of the human observer in the explanation process.
Methods: A literature search was performed in Web of Science (WoS) to identify studies that applied saliency maps to explain imaging-based AI models for classification of rheumatic diseases in patient imaging exams. Full-text articles and conference abstracts published in English between the 1st of January 2023 and the 14th of January 2025, discussing studies with a minimum of 100 subjects imaged on any modality (CT, MRI, X-Ray, US) and covering any rheumatic disease were considered. The references were ordered on the number of WoS citations. Abstracts and, if needed full-texts, were reviewed by one author (JN) to select the studies that applied saliency maps to rheumatic disease related classification tasks. Additional data was leveraged from one of our own studies to illustrate some of the selection biases using unpublished work [5]. Both authors reviewed the figures comprising saliency maps, the textual interpretation of the XAI outputs and the associated claims with the respect to the trustworthiness or reasoning of the studied AI model in the full text articles.
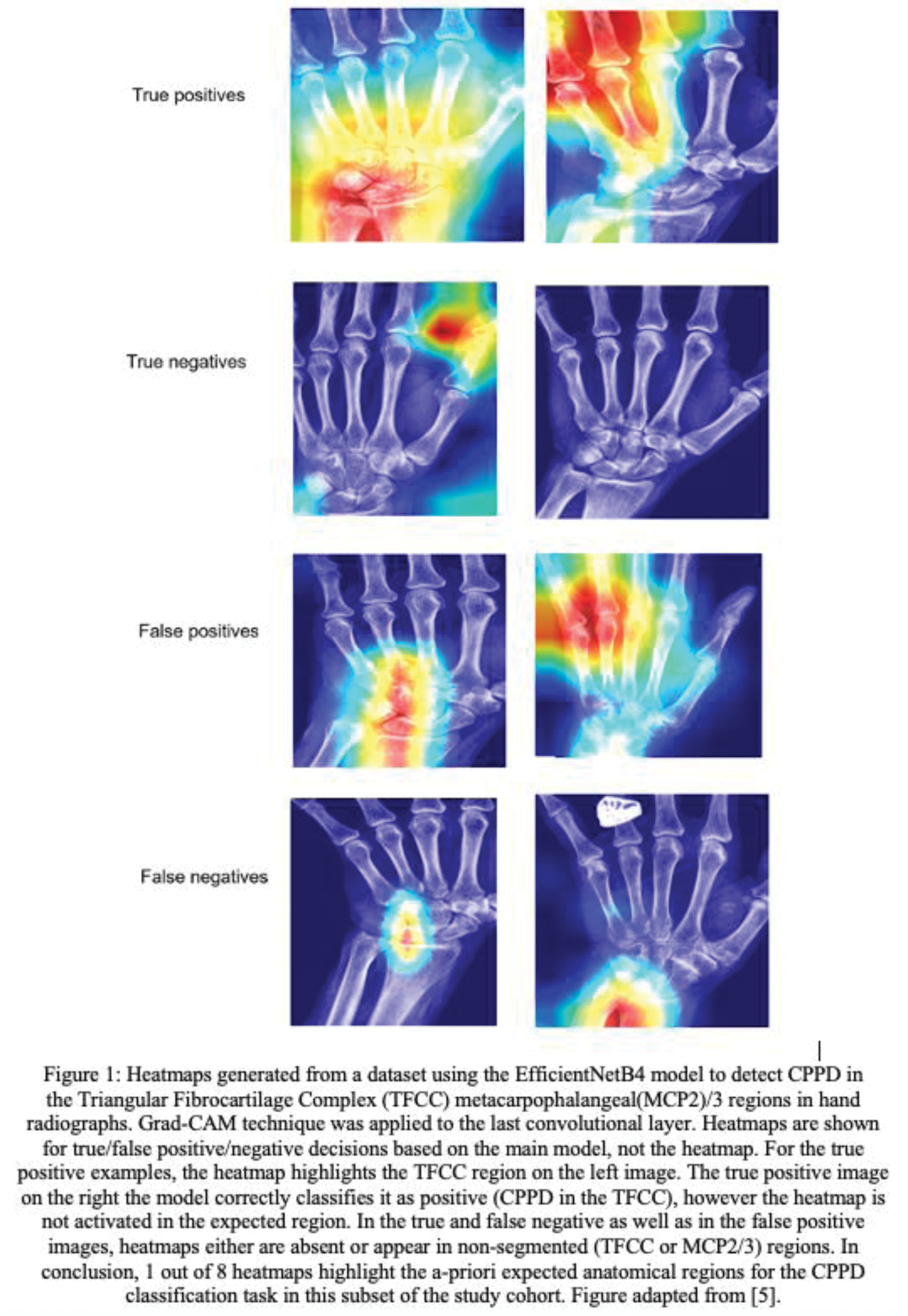
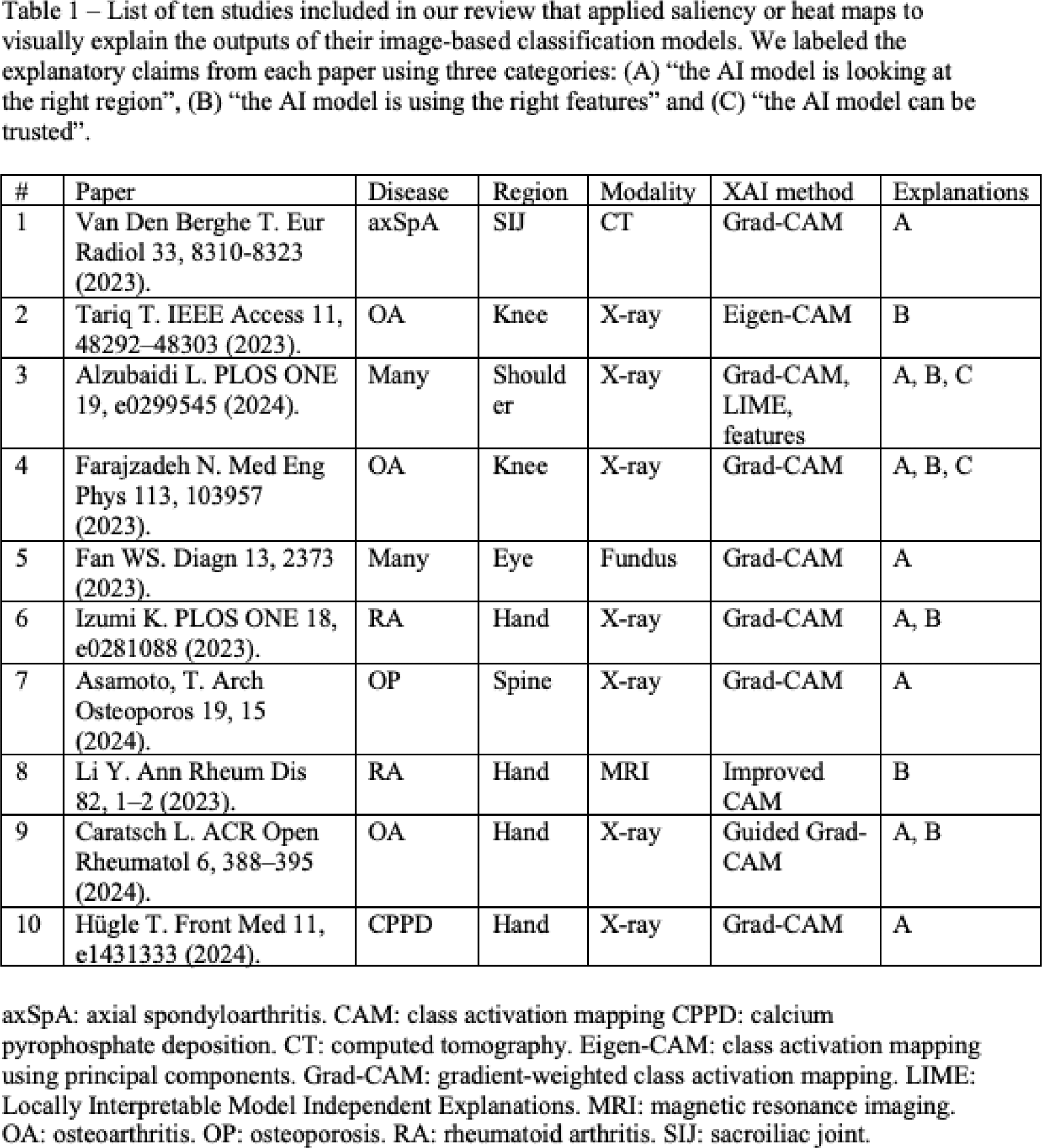
Results: The literature search identified 438 unique references of which 108 were reviewed for finding ten eligible studies that applied saliency maps to explain image-based classification models (Table 1). The AI models were built for various rheumatic diseases, i.e., OA (3), RA (2), axSpA (1), CPPD (1), osteoporosis (1) and multiple (2), and using different imaging modalities, i.e., X-ray (7), CT (1), MRI (1) and hyperspectral ophthalmoscope images (1). Eight studies used the Grad-CAM method to produce saliency maps, two a variation of class activation mapping (CAM), and one study additionally applied two other XAI methods. The saliency maps were applied to between one and 18 example cases, representing less than 1% of the study cohort. We found that saliency maps are interpreted by the authors using three categories of explanatory claims: (A) “the AI model is looking at the right region” (8/10), (B) “the AI model is using the right features” (6/10) and (C) “the AI model can be trusted” (2/10). Four papers critically discussed the saliency maps by highlighting the presence of saliency signals in unexpected regions and one paper acknowledged that saliency maps cannot explain the rationale behind a classification nor allow to understand the reason behind incorrect outputs. None of the papers investigated the consistency of saliency maps. We argue that all interpretations leveraged human prior knowledge to confirm positive findings and often ignored inconsistent saliency signals, subject to confirmation and selection biases, respectively, by the human observers. Figure 1 shows saliency maps of a model used for CPPD detection on hand radiographs [5]. Saliency maps can be out of focus (e.g., true positive, top-right picture showing saliency out of focus for MCP4/5) and are not reliable in most of the examples.
Conclusion: XAI methods risk leading to unwarranted trust in the merits of the studied AI models and to use saliency maps like signals of imaging indicating a pathological process such as osteoblast-activity in SPECT-CT. Clinicians evaluating or using AI models should exhibit caution when attempting to explain a black-box AI model using saliency maps. Human observers interpreting the XAI outputs are subject to various biases and crucially, are unable to explain why and how the AI model produced its outputs. Previous work showed that humans cannot explain their own decisions accurately. Hence, we question whether it’s worth attempting to explain AI models. Instead, we recommend focusing on rigorously testing the performance and reliability in well-designed validation studies.
REFERENCES: [1] van der Velden BHM. Med Image Anal 79, e102470 (2022).
[2] Stoel BC. Nat Rev Rheumatol 20, 182–195 (2024).
[3] Ghassemi M. Lancet Digit Health 3, 11, e745–e750 (2021).
[4] Cadario R. Nat Hum Behav 5, 1636–1642 (2021).
[5] Hügle T. Front Med 11, e1431333 (2024).
Acknowledgements: NIL.
Disclosure of Interests: Joeri Nicolaes shareholder of UCB Pharma, employee of UCB Pharma, Thomas Hügle AbbVie, GSK, Roche, Novartis, BMS, Eli Lilly, Janssen, UCB, Pfizer, Werfen, Atreon, Vtuls, Fresenius Kaby, Eli Lilly, Novartis.
© The Authors 2025. This abstract is an open access article published in Annals of Rheumatic Diseases under the CC BY-NC-ND license (