fetching data ... 
Background: Patient-reported outcomes (PROs) are often indirectly referenced in physician notes. Extracting PROs, such as pain scores, from physician notes is vital for understanding the patient’s perspective on their health and treatment effectiveness. While these notes may be long and contain a lot of medical jargon, as well as abbreviations, they also offer valuable insights for tailoring care, tracking outcomes over time, and improving clinical decision-making. Large language models (LLMs) have become important tools to quickly extract and summarize large bodies of text from many different domains. However, they still require the application of prompt engineering techniques to consistently receive one’s desired output. Prompt engineering is the process of designing inputs in a large language model to produce desired outputs.
Objectives: Our objective was to apply prompt engineering techniques to a pretrained LLM to extract patient reported pain in Osteoarthritis (OA) patients.
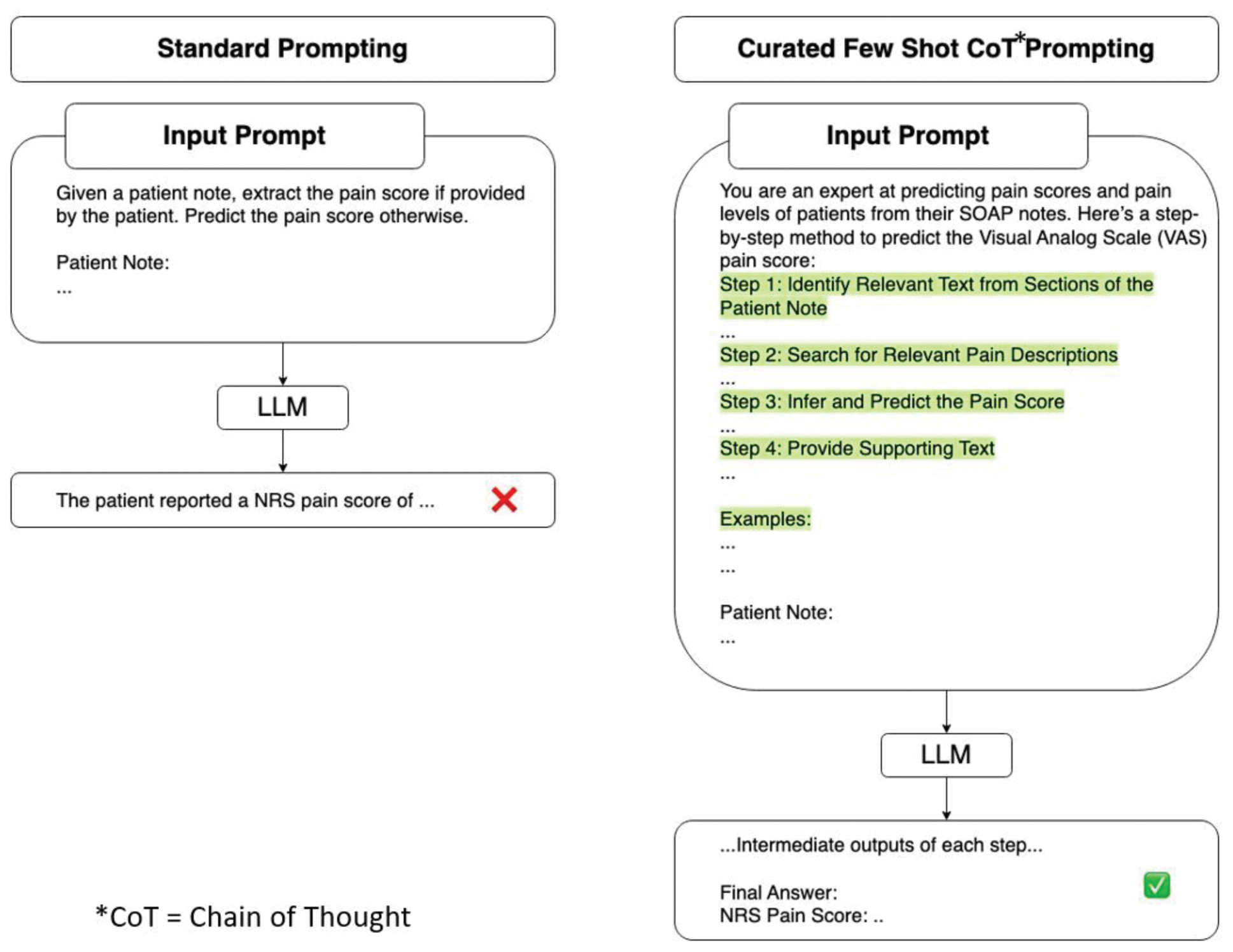
Methods: We utilized electronic medical record notes from patients with end-stage osteoarthritis enrolled prospectively in a registry prior to undergoing total knee arthroplasty. Two types of notes were analyzed: pre-operative notes from internal medicine (IM) visits and notes from orthopedic(ortho) surgeon visits. A trained abstractor extracted the patient-reported pain from those notes that had pain scores explicitly stated. For those notes that did not have pain scores stated, a board-certified physician was asked to predict pain scores based on the information in the notes. The full text of the notes was processed using the Llama 3.2 – 90B model, with a temperature set at 0 and top P set at 1. A prompt was fine-tuned to extract the patient-reported Visual Analog Scale (VAS) pain score or numeric pain rating (NRS), or pain score from the notes (Figure 1). Prompt engineering techniques, such as Chain of Thought and Few Shot examples, were employed. After optimizing and fine-tuning the prompt on a subset of notes, it was applied to the entire dataset. As part of the experiment, outside their visit, patients were asked a 0–10 pain score on the day of the peri-operative visit. We calculated Kendall’s Tau-b, a non-parametric statistic used to measure the ordinal correlation between (1) the LLM and trained abstractor for notes with stated pain scores and (2) for those that do not have pain scores in the notes. We next compared LLM pain prediction with patient-reported pain scores and compared physician prediction with patient-reported pain scores.
Results: We identified 133 internal medicine notes and 66 orthopedic consultation notes that explicitly stated the pain scores, either in text or in table format (Figure 2). In comparisons between pain scores extracted via a trained abstractor and the LLM, we observed a strong correlation in internal medicine notes and an even stronger correlation in orthopedic notes (IM notes – Kendall’s Tau(Kt) = 0.81, p < 0.0001; Ortho notes – Kt = 0.9, p < 0.0001). In internal medicine notes, 18 notes had a pain score written as 0 because the question was unanswered by patients, causing the EMR system to default to zero. In most cases, the LLM recognized and flagged these abnormalities. Thus, as a sensitivity analysis, we excluded the default zero, and we had a perfect correlation (Kt = 1, p < 0.0001). For notes lacking explicit pain scores, the LLM predicted scores for 26 preoperative internal medicine notes and 93 orthopedic notes. When comparing LLM-predicted pain scores to patient-reported pain scores obtained outside of the visit, the correlations were weak (IM notes – Kt = 0.17, p = 0.30; Ortho notes – Kt = 0.09, p = 0.30). However, when a board-certified physician was asked to predict the same scores, the correlation was also weak (IM – Kt = 0.12, p = 0.46; Ortho notes – Kt = 0.13, p = 0.12).
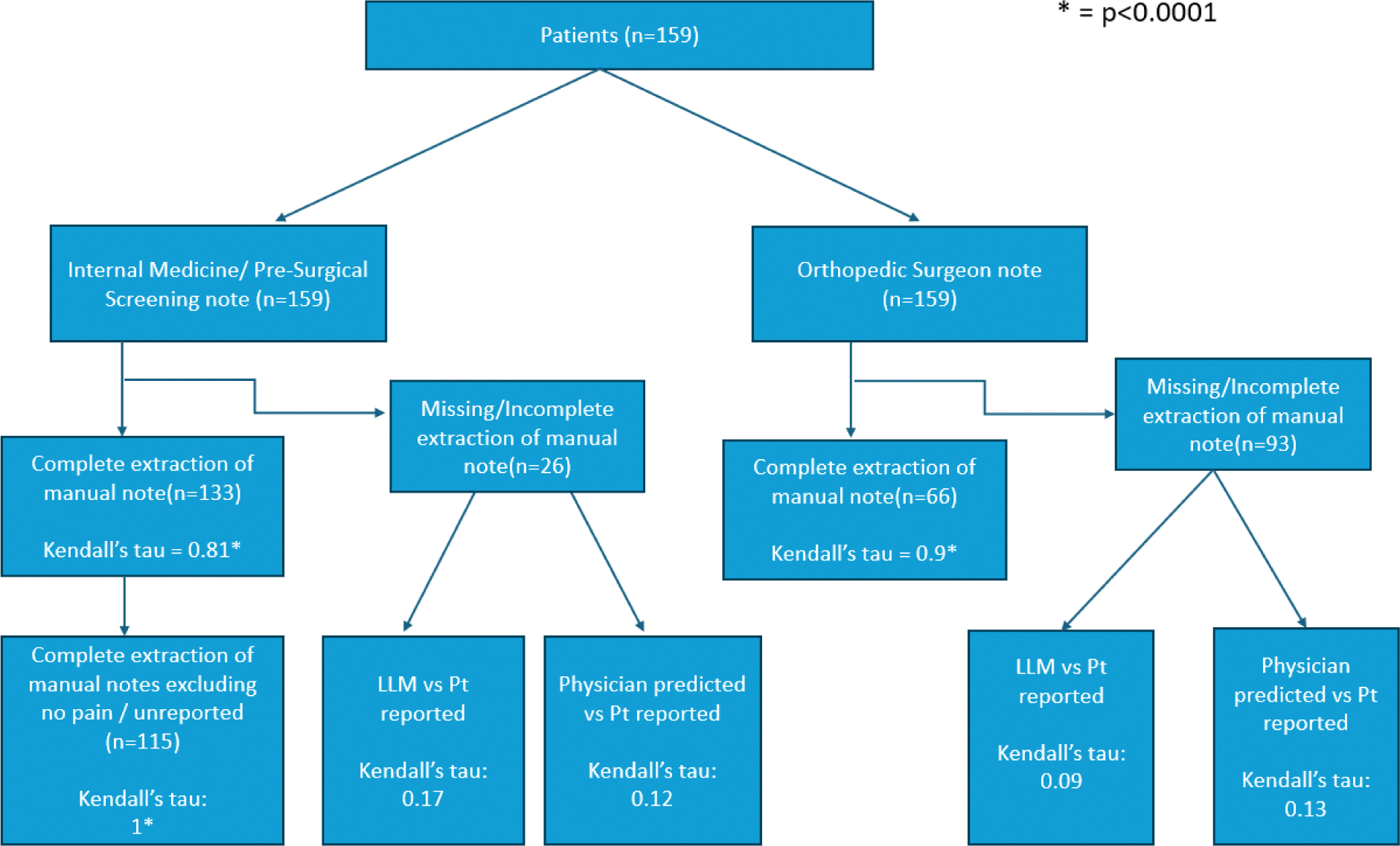
Conclusion: When PROs of numeric pain rating, visual analog scale, or overall pain rating are explicitly documented in the chart, the LLM accurately extracts the information. However, in cases where pain scores are absent, the LLM’s predictions perform no better than those of board-certified physicians using the same data. It is important to note that both the LLM and physicians perform poorly in such scenarios. This approach demonstrates an efficient, out-of-the-box method for extracting PROs using prompt engineering, significantly reducing the time and effort required to develop a custom system from scratch. Automating PRO extraction minimizes the need for patients to repeatedly complete questionnaires, which can reduce inconsistencies, alleviate patient burden, and enhance efficiency. Future directions include incorporating real-time clinician feedback to iteratively improve the model’s performance and using this tool to track patient pain scores over time for clinical and research purposes.
REFERENCES: NIL.
Acknowledgements: Bella Mehta is funded by the NIH NIAMS K23 career development award (1K23AR082991- 01A1).
Disclosure of Interests: Jainesh Doshi: None declared, Stephen Batter: None declared, Yiyuan Wu: None declared, Alice Santilli: None declared, Sandhya Shri Kannayiram: None declared, Susan M. Goodman UCB, Regenosine, UCB, Novartis Corporation Pharmaceuticals, Bella Mehta Horizon Advisory Board.
© The Authors 2025. This abstract is an open access article published in Annals of Rheumatic Diseases under the CC BY-NC-ND license (