fetching data ... 
Background: Rare rheumatic diseases are challenging to diagnose due to their complex and often atypical presentations. Diagnostic decision support systems (DDSS), including large language models (LLMs) and symptom checkers (SCs), offer potential to assist both laypersons and healthcare professionals in improving diagnostic accuracy and accelerating the diagnostic process.
Objectives: This study evaluated the diagnostic accuracy and usability of four LLMs and three SCs, encompassing free, subscription-based, and locally hosted DDSS, for identifying rare rheumatic diseases and their differential diagnoses.
Methods: Sixty rare disease vignettes were analyzed, including 50 sourced from published literature and 10 unpublished real-world cases to represent diagnostically challenging cases. The cases spanned connective tissue diseases (n=13), autoinflammatory conditions (n=9), vasculitides (n=11), immunodeficiencies (n=5), storage diseases (n=5), and other differential diagnoses (n=17). Each DDSS –including LLMs (Claude 3.5 Sonnet, ChatGPT-4o, Gemini 1.5 Pro, and Llama 3.2) and SCs (Ada, Symptoma and Isabel Pro)–was provided with anamnestic information to generate up to five disease suggestions per vignette. Case completion time for each vignette and DDSS was timed. Diagnostic suggestions were rated by three blinded rheumatologists. In case of disagreement, discrepancies were resolved in discussions between rheumatologists. Results were reported as proportion of vignettes with the identical (i) or a plausible (p) diagnosis as the top suggestion (Top1) and within the top five suggestions (Top5). Identical diagnoses were scored with two points, plausible diagnoses with one point, contributing to a total diagnostic score. Case completion time for each vignette and DDSS was also measured. A two-proportions test was used to compare the rate of identical diagnoses of all LLMs against all SCs.
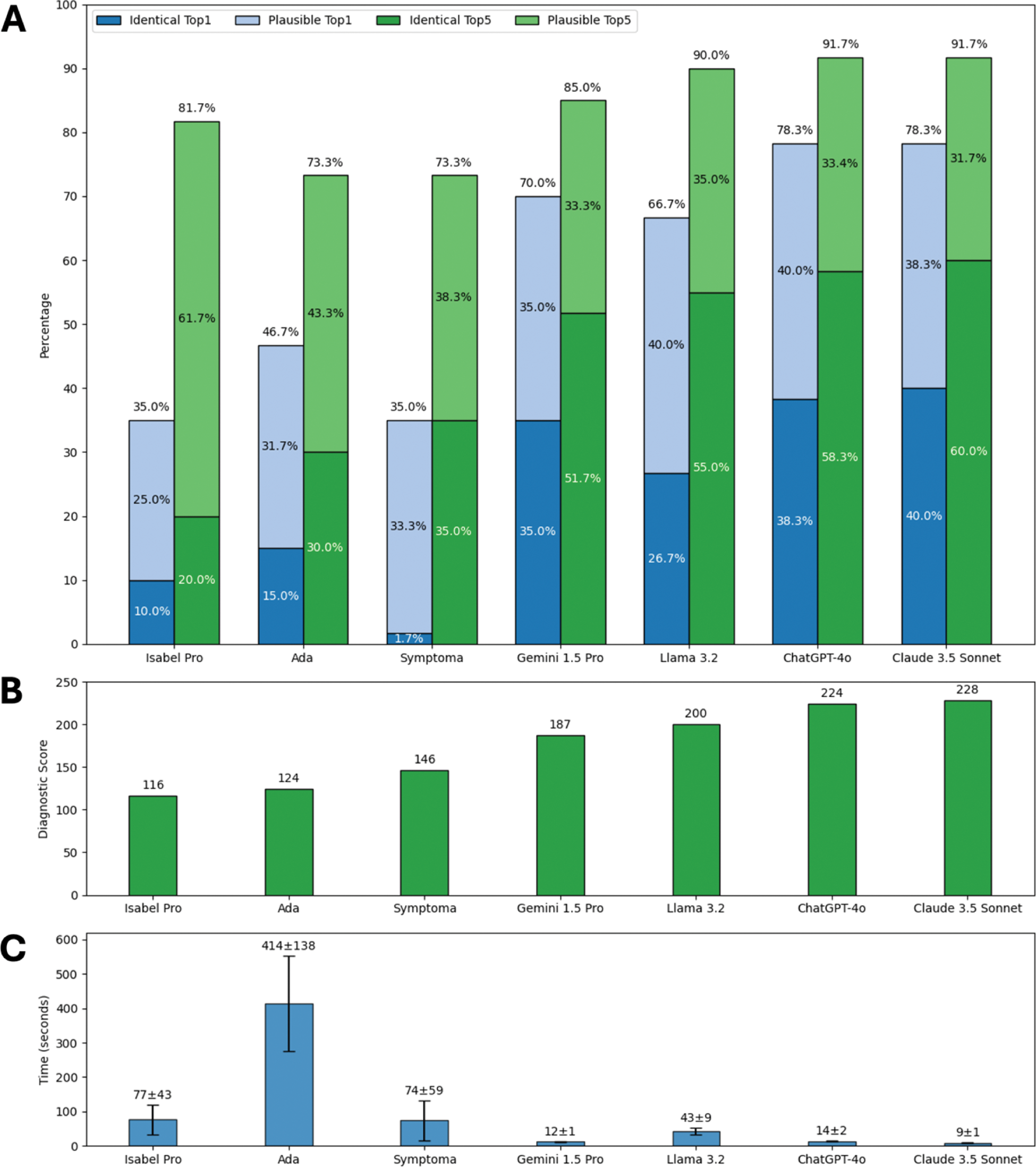
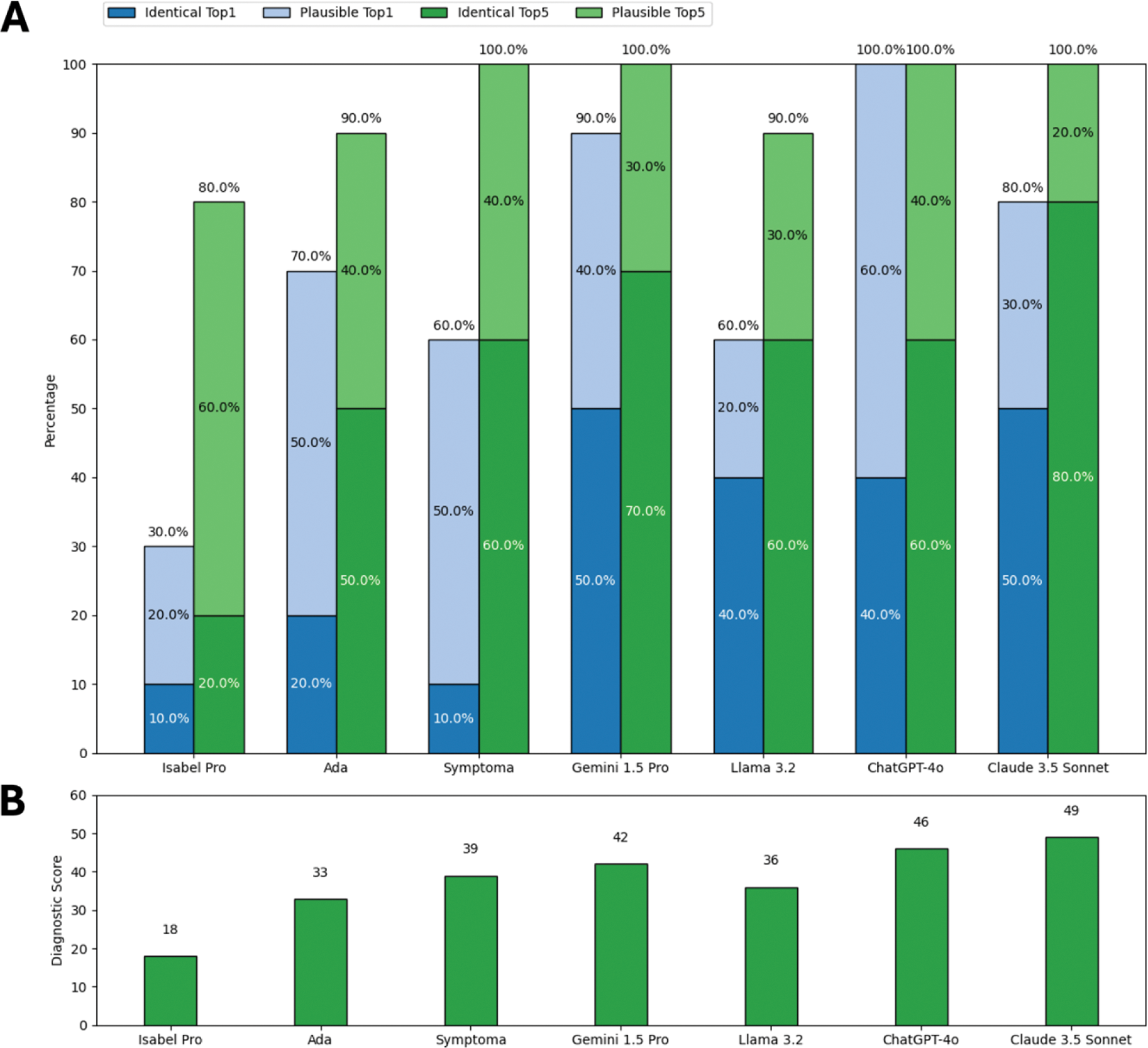
Results: Overall diagnostic accuracy varied widely with LLMs generally outperforming SCs (Figure 1A, B). LLMs significantly more often suggested an identical top diagnosis compared to SCs; X²(1) = 37.23, p < 0.001. LLMs were also more time-efficient (Figure 1C) averaging 20 seconds per case compared to 189 seconds for SCs. Performance trends were consistent for the unpublished cases (Figure 2), which were definitely not part of DDSS training data. Claude 3.5 Sonnet emerged as the top-performing DDSS, achieving the highest overall score (228) and unpublished cases score (49), as well as the highest rates of identical diagnoses (overall Top1: 40.0%, Top5: 60.0%; unpublished cases Top1: 50.0%, Top5: 80.0%).
Conclusion: LLMs demonstrated superior diagnostic accuracy and efficiency compared to SCs, including free and subscription-based systems. Notably, the locally hosted Llama 3.2, while slightly less powerful than cloud-based LLMs, showed promising diagnostic performance, suggesting the feasibility of secure, on-premises DDSS deployment. Future studies should focus on integrating LLMs into clinical workflows to evaluate their impact on real-world diagnostic accuracy. Additionally, efforts should be made to enhance their performance further by incorporating techniques such as retrieval-augmented generation.
Percentage of vignettes with the identical (dark colors) or a plausible (light colors) diagnosis as the top suggestion (blue) and within the top five suggestions (green) (A), total diagnostic scores according to DDSS (B), and average (SD) case completion time per case (C) of all cases.
Percentage of vignettes with the identical (dark colors) or a plausible (light colors) diagnosis as the top suggestion (blue) and within the top five suggestions (green) (A), and total diagnostic scores according to DDSS (B) for unpublished cases.
REFERENCES: NIL.
Acknowledgements: NIL.
Disclosure of Interests: Phillip Kremer: None declared, Hannes Schiebisch: None declared, Fabian Lechner Lilly, Isabell Haase: None declared, Lasse Cirkel: None declared, Sebastian Kuhn MED.digital, Martin Krusche: None declared, Johannes Knitza Abbvie, Vila Health, Abbvie, AstraZeneca, BMS, Boehringer Ingelheim, Chugai, Fraunhofer, Fachverband Rheumatologische Fachassistenz, GAIA, Galapagos, GSK, Janssen, Lilly, Medac, Novartis, Pfizer, Rheumaakademie, Sanofi, Sobi, UCB,, Vila Health, GAIA, GSK, Vila Health, Abbvie, GSK, Vila Health, Abbvie, GSK, Vila Health.
© The Authors 2025. This abstract is an open access article published in Annals of Rheumatic Diseases under the CC BY-NC-ND license (