fetching data ... 
Background: Rheumatology is a field with considerable diagnostic challenges, characterized by rare and complex multisystem diseases that frequently present with a variety of symptoms, multiple, often nonspecific. Thus, physicians face difficulties in establishing timely and accurate diagnoses. Here, large language models (LLMs) could potentially assist by generating concise, context-specific responses and accelerate the diagnostic process. Nonetheless, clinicians are facing a plethora of available LLMs for decision support while comparative studies are lacking.
Objectives: To compare the diagnostic performance of ChatGPT-5 Thinking, a general-purpose reasoning LLM, OpenEvidence, a free medical RAG-based LLM program, and Prof. Valmed, a subscription-based, RAG-based LLM program, certified as a medical device.
Methods: A total of 60 vignettes encompassing rare rheumatic conditions and their differentials were submitted via a standardized prompt, yielding five top-ranked diagnoses with associated diagnostic probabilities. Suggested diagnoses were reviewed by blinded rheumatologists, who rated them as identical, plausible, or diagnostically different. Diagnostic accuracy was quantified by the proportions of identical and plausible diagnoses and by an aggregate diagnostic score. Descriptive methods were used for analysis. Differences between groups in the frequency of identical top diagnoses were analyzed using Cochran’s Q test, followed by post-hoc McNemar tests. Processing time was recorded.
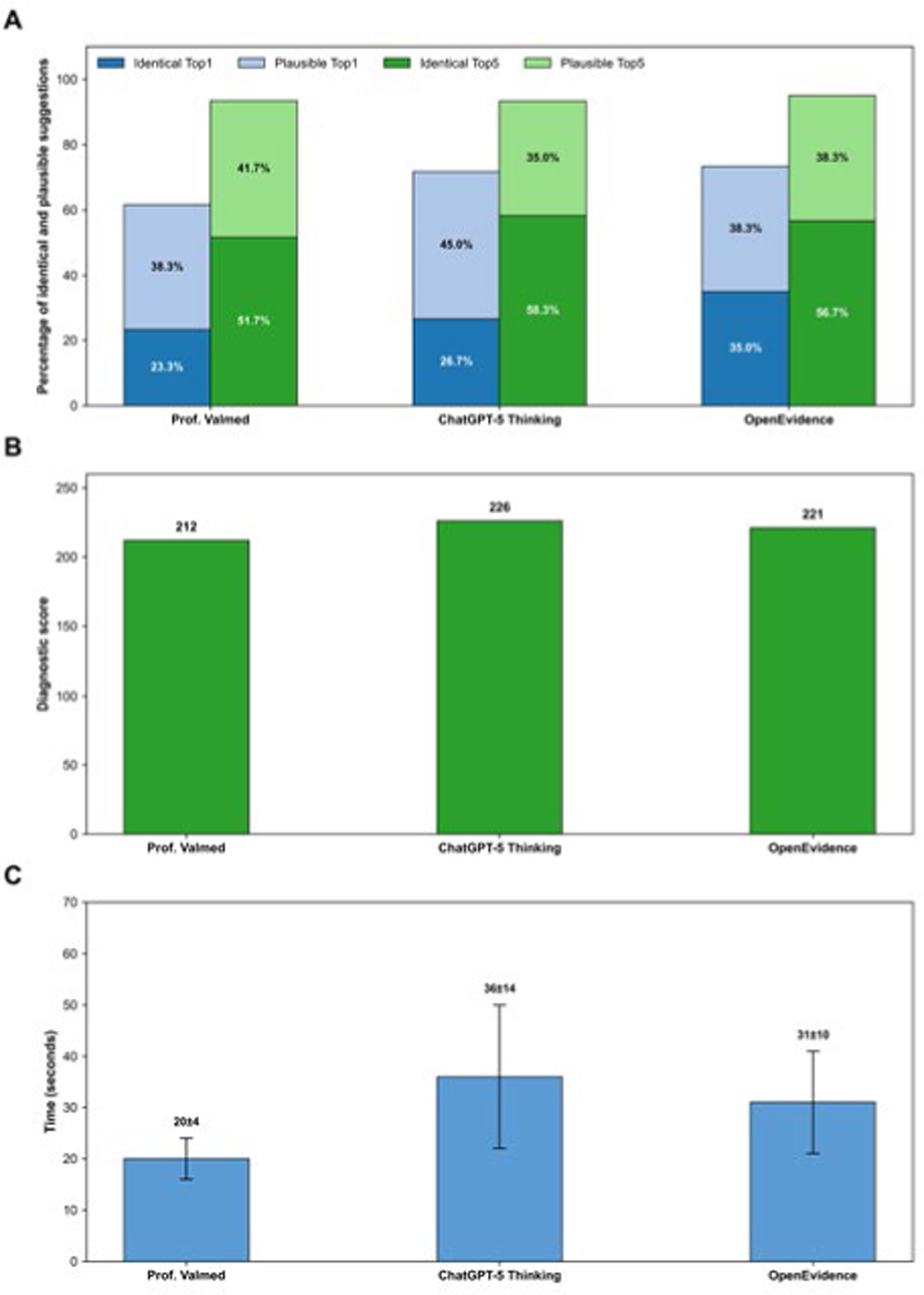
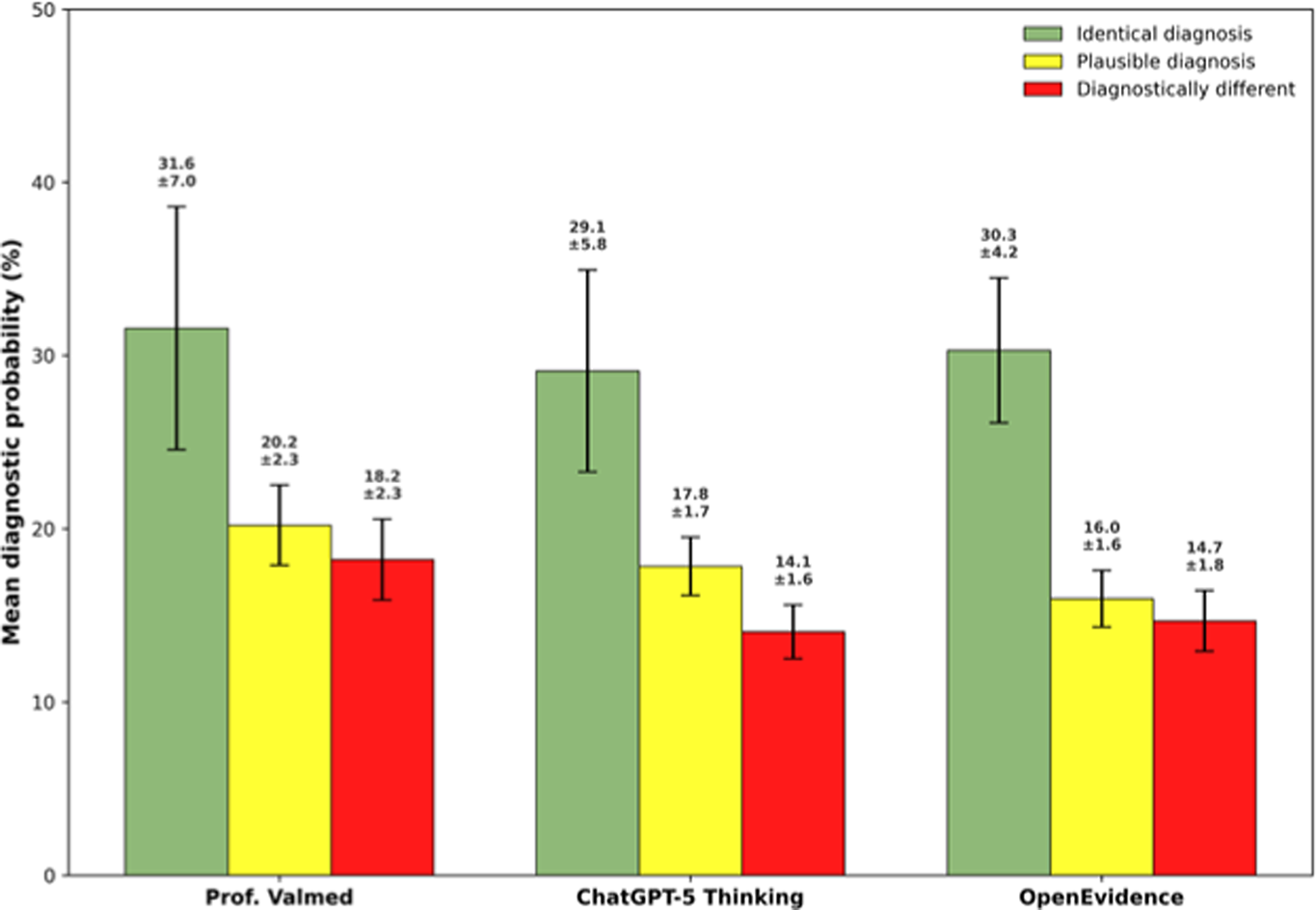
Results: OpenEvidence showed the greatest proportion of identical top diagnoses (35.0%), compared with 26.7% for ChatGPT-5 Thinking and 23.3% for Prof. Valmed (Figure 1A). However, post-hoc McNemar tests (Holm-adjusted) did not reveal significant differences. In contrast, ChatGPT-5 Thinking led in total diagnostic score (226), ahead of OpenEvidence (221) and Prof. Valmed (212) (Figure 1B). Mean processing times varied between 20 and 36 seconds (Figure 1C). Across all systems, diagnostic probabilities were substantially higher for identical than for different diagnoses (Figure 2).
Conclusions: Even as a purpose-built, certified, subscription-based RAG system, Prof. Valmed did not outperform either the non-RAG, general-purpose ChatGPT-5 Thinking or the free, RAG-based OpenEvidence in a clinically meaningful way. This implies that retrieval augmentation, certification, and cost, taken alone, do not guarantee superior performance. Ongoing, rigorous evaluation, especially in real-world clinical settings, is needed to guide safe and cost-effective integration of LLM-based diagnostic support into rheumatology practice.
Percentage of vignettes with the identical (dark colours) or a plausible (light colours) diagnosis as the top suggestion (blue) and within the top 5 suggestions (green) (A), total diagnostic scores according to system (B), and mean (SD) case processing time (C).
Mean diagnostic probabilities for all suggested diagnoses across identical, plausible and diagnostically different categories.
REFERENCES: NIL.
Acknowledgments: NIL.
Disclosure of Interests: Phillip Kremer: None declared, Emily Langballe: None declared, Isabell Haase Abbvie, AstraZeneca, AlphaSigma, GSK, Janssen, Medac, Lilly, Novartis, Sobi, UCB, Abbvie, AstraZeneca, AlphaSigma, GSK, Janssen, Medac, Lilly, Novartis, Sobi, UCB, Jonathan Bamberger: None declared, Sebastian Kuhn: None declared, Martin Krusche Novartis, Sobi, Abbvie, Medac, Lilly, Roche/Chugai, UCB, Novartis, Sobi, Abbvie, Medac, Lilly, Roche/Chugai, UCB, Johannes Knitza: None declared.