fetching data ... 
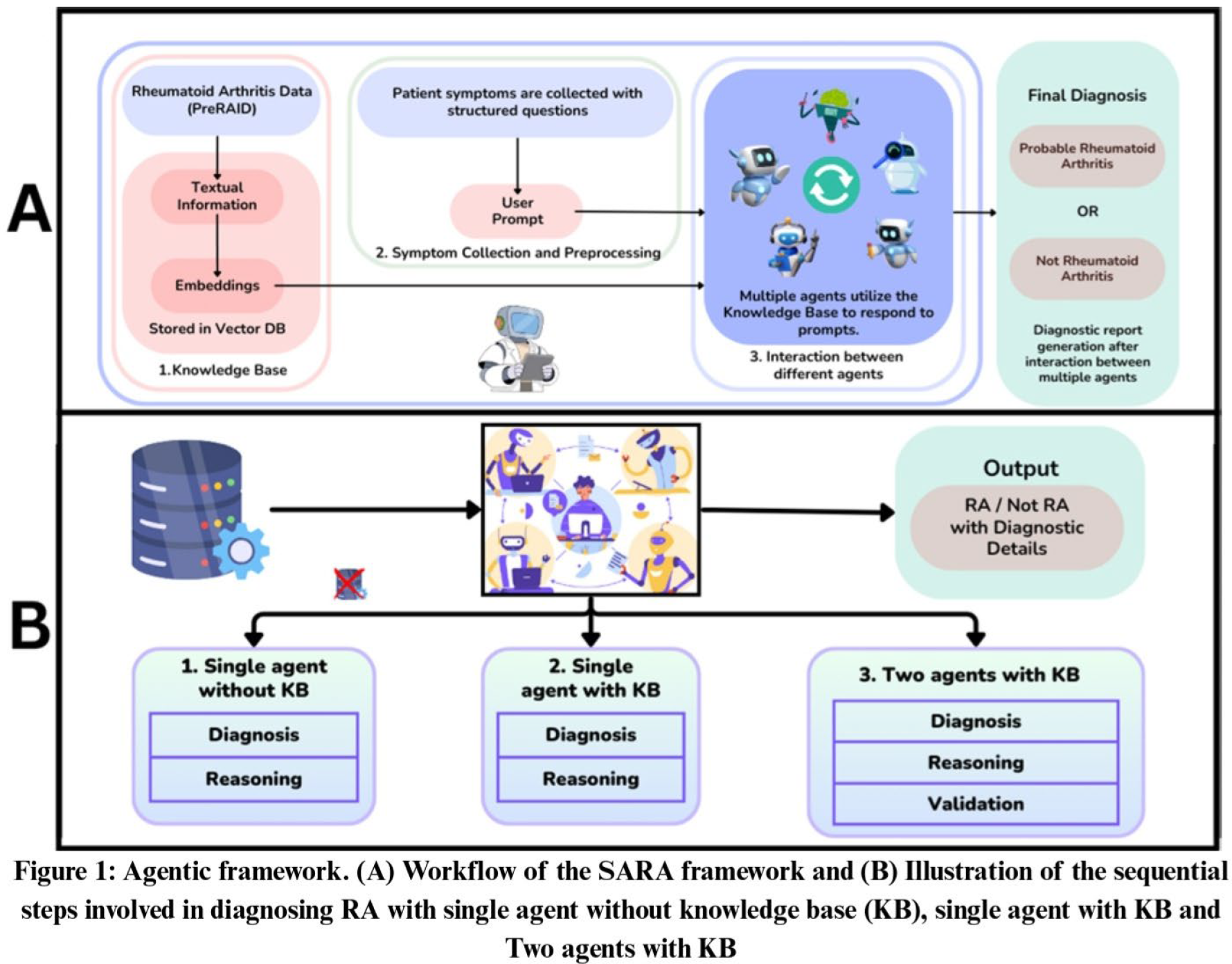
Background: Rheumatoid arthritis (RA) affects ~1% of the global population. Indian patients often present late with deformities. Artificial Intelligence-driven Large Language Models (LLMs), deployable via mobile phones, offer screening solutions. However, clinicians may not be confident in these diagnoses until they are sure of the reasoning behind these diagnoses. Various agentic frameworks were explored to identify the most effective models for screening for RA. Then the reasoning behind each diagnosis was manually validated ( Figure 1 ).
Objectives: To evaluate and compare the diagnostic accuracy of different Large Language Models (LLMs) for screening of rheumatoid arthritis using multiple agentic frameworks, and to assess the validity and clinical acceptability of the reasoning provided by these models through manual evaluation by rheumatologists.
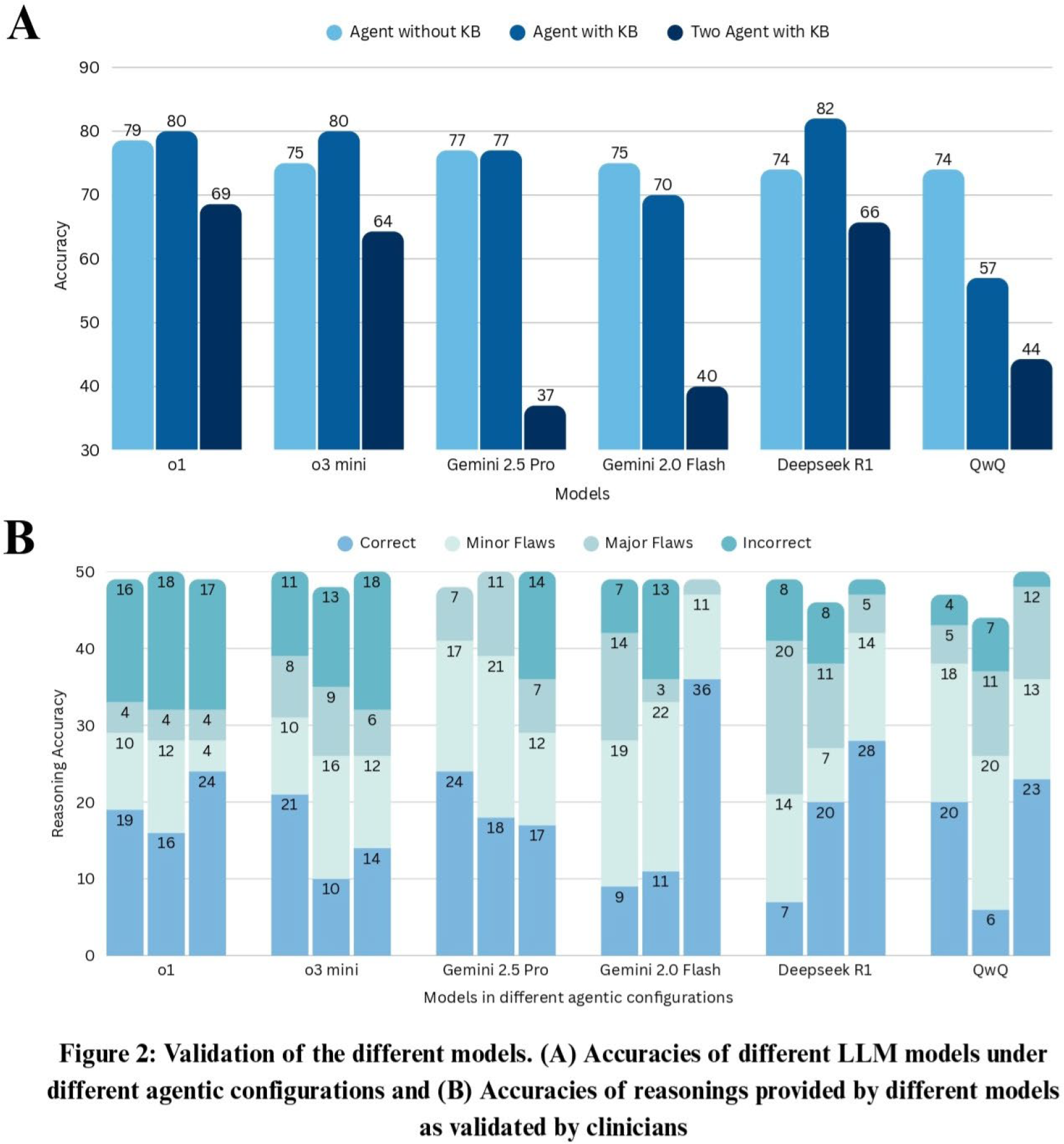
Methods: A proprietary dataset, PreRAID (Pre-Screening Rheumatoid Arthritis Information Database), was developed from patients with physician-confirmed RA. The dataset included 280 cases for knowledge base (KB) and 70 for testing, using Neo4j vector database for embedding-based retrieval. Six LLMs were evaluated: four closed-source (OpenAI o1, OpenAI o3-mini, Gemini 2.5 Pro, Gemini 2.0 Flash) and two open-source (QwQ, Deepseek R1 70B). Models were trained incrementally with 10 additional cases per cycle until performance saturation, then diagnosed 50 new cases across three configurations: single agent without KB access, single agent with retrieval-augmented generation (RAG), and dual-agent setup ( Figure 1B ). Reasoning quality was assessed by three rheumatologists. For the validation of reasoning, three agentic frameworks for the six LLM was assessed ( Figure 2B ) for 60 patients each. For each of these 900 pages (entries), two rheumatologists independently assessed (1) reasons provided in favour of RA, (2) reasons provided against the diagnosis of RA and (3) ultimately why the diagnosis of RA was accepted or rejected. Overall, the rheumatologists categorized each output as (a) correct, (b) having minor flaws, (c) having major flaws or (d) completely incorrect. In case of disagreement between the two rheumatologists, the third arbitrated after joint discussion.
Results: First the accuracy of the agentic frameworks was established ( Figure 2A ). DeepSeek R1 achieved highest accuracy (82%) in single-agent with KB, followed by o1 and o3-mini (80% each). Two-agent setups showed decreased accuracy, particularly for Gemini 2.5 Pro (37%) and Gemini 2.0 Flash (40%). Reasoning quality was suboptimal across all models, with Gemini 2.0 Flash (36/50) and DeepSeek R1 (28/50) showing most correct justifications. However, models with the best reasoning (72% correct) had poor diagnostic accuracy (37%). Excluding minor flaws, the best reasoning was in the single agentic framework without the KB. This may seem to imply that fine tuning the models appears to align the “reasoning” with the experts, but at the cost of the actual correct diagnosis.
Conclusions: Misalignment between LLM diagnostic accuracy and reasoning validity in RA screening raises concerns that need to be addressed before clinical deployment. If a correct diagnosis is supported by robust reasoning, physicians would be more confident in accepting these. Thus, current solutions may be good enough for screening but much needs to be done to establish explainable AI paradigms before AI-assisted clinical decision-making can be used more widely.
REFERENCES: NIL.
Acknowledgments: NIL.
Disclosure of Interests: Sarthak Verma: None declared, Avarna Agarwal: None declared, Prakashini Mruthyunjaya: None declared, Umakanta Maharana: None declared, Murari Mandal: None declared, Prasanta Padhan: None declared, Sakir Ahmed SA has received honorarium as speaker from Alkem, Cipla, Pfizer, DrReddy, SunPharma, Torrent, Ipca and was on the advisory board of Jansen.