fetching data ... 
Background: Systemic lupus erythematosus (SLE) is a chronic autoimmune disease with heterogeneous clinical manifestations that require frequent assessment of disease activity to guide treatment decisions under a treat-to-target strategy. The SLEDAI-2k is commonly used to quantify disease activity; however, its application in routine clinical practice is limited by the time required for data extraction, scoring, and documentation. Automated tools based on artificial intelligence, particularly large language models (LLMs), could potentially assist clinicians by facilitating faster and more standardized disease activity assessments using information from routine clinical notes.
Objectives: To evaluate the clinical feasibility of using large language models to support SLEDAI-2k disease activity assessment from routine clinical documentation in patients with SLE.
Methods: A pilot, cross-sectional study was conducted using anonymized clinical progress notes from patients with SLE. Notes were generated during routine care by rheumatologists and rheumatology trainees who were unaware of the study purpose. An experienced rheumatologist calculated the SLEDAI-2k score for each note, which served as the clinical reference. The same notes were analyzed by five LLM platforms (ChatGPT, Gemini, DeepSeek, Claude, and Perplexity) using standardized instructions to calculate SLEDAI-2k scores. Model outputs were compared with the reference standard to determine the proportion of correct scores. Incorrect scores were classified as underestimations or overestimations. Descriptive statistics were used.
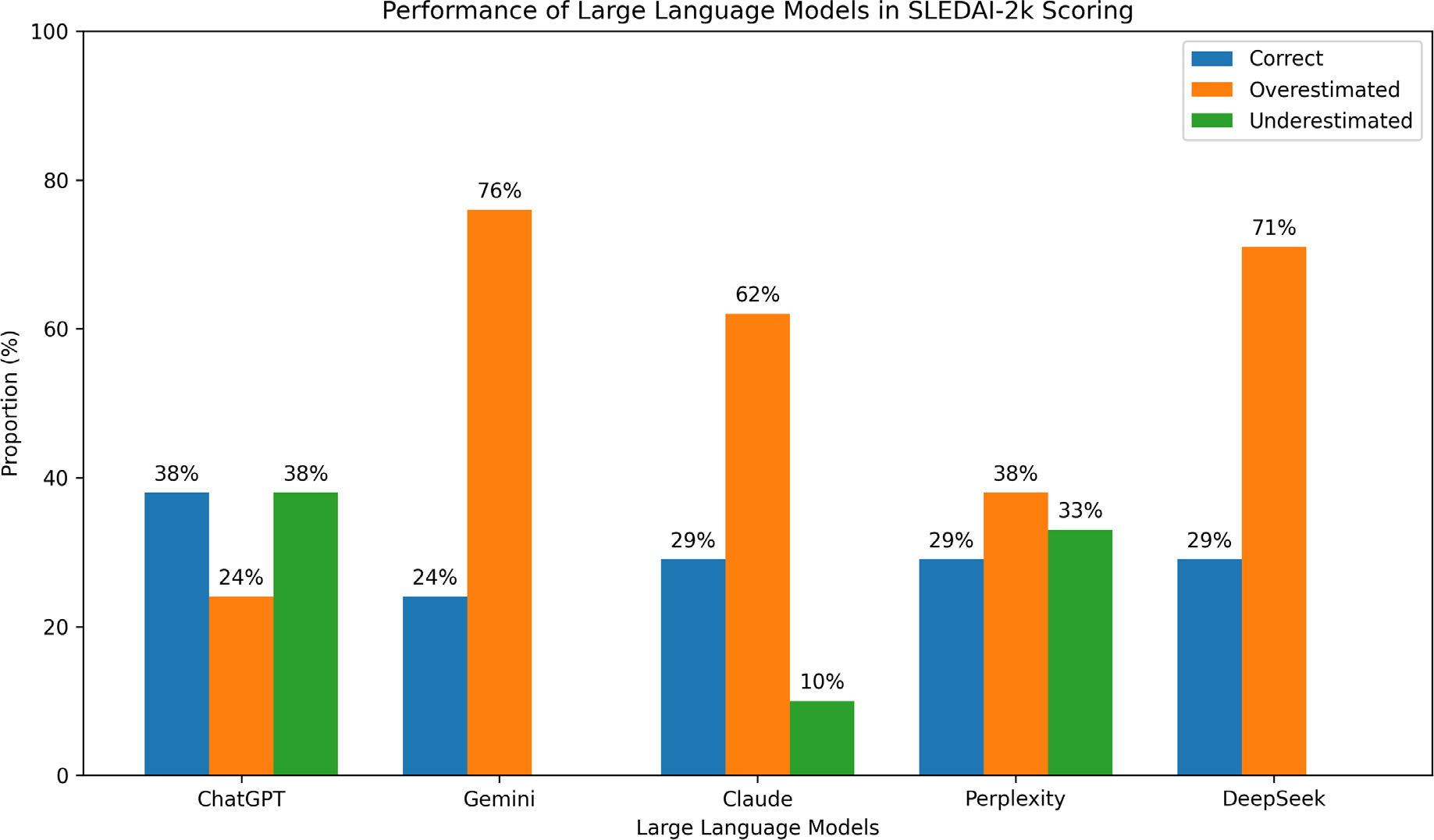
Results: Twenty-one clinical progress notes were analyzed. None of the evaluated LLMs achieved an accuracy above 50% when compared with the rheumatologist-calculated SLEDAI-2k scores. ChatGPT demonstrated the highest agreement with the reference standard, with 38.1% correct scores, whereas Gemini showed the lowest accuracy (23.8%). DeepSeek, Claude, and Perplexity each achieved an accuracy of 28.6%. Clinically relevant discrepancies were observed: ChatGPT more frequently underestimated disease activity, while Gemini, DeepSeek, and Claude predominantly overestimated SLEDAI-2k scores. Perplexity showed a more balanced distribution of under- and overestimation.
Conclusions: In this clinical pilot study, large language models showed limited agreement with rheumatologist-calculated SLEDAI-2k scores derived from routine clinical notes. At present, general-purpose LLMs should not be used independently for clinical decision-making in SLE disease activity assessment. However, targeted development and clinical training of specialized models may enable future integration of AI-based tools to support, rather than replace, clinician-led disease activity evaluation in everyday rheumatology practice.
Accuracy and error rates of SLEDAI-2k scores calculated by different large language models compared with a board-certified rheumatologist.
REFERENCES: NIL.
Acknowledgments: NIL.
Disclosure of Interests: None declared.