fetching data ... 
Background: Health literacy is a key determinant of favorable outcomes in rheumatic and musculoskeletal diseases (RMDs). Among them patients with connective tissue diseases (CTDs) constitute a particularly relevant subgroup due to their complex, multisystem conditions. However, many patients with CTDs struggle to access trustworthy, comprehensible health information. Growing shortages in rheumatologists and the widespread use of “Dr Google” have shifted information seeking to the web, where the quality of content is highly variable. Recently, large language models (LLMs) have emerged as a new medium for patient counselling, but their performance on real CTD patient questions has not been systematically evaluated.
Objectives: To compare the quality of answers generated by contemporary general-purpose LLMs with information obtained via Google Search for the most frequently asked questions (FAQs) from patients with systemic lupus erythematosus (SLE), idiopathic inflammatory myopathy (IIM), sjögren’s disease (SjD), and systemic sclerosis (SSc).
Methods: In this prospective single-center study, with support from patient advocacy groups, we compile twenty highly relevant disease-related questions for each CTD and submitted them to three LLMs (Claude 4.0 Sonnet, ChatGPT-5, Gemini 2.5 Pro) and to Google Search. For each LLM, consolidated answer sets were created and anonymised for rating. Adult patients fulfilling current EULAR/ACR classification criteria for the four CTDs (five per disease) and a panel of five board-certified rheumatologists independently evaluated the answers using standardized forms. Primary outcome was overall impression, ranked across systems (I–IV, I = best). Patient-reported secondary outcomes, empathy, trustworthiness, and comprehensibility, were rated on a 5-point Likert scales (1 = excellent, 2 = good, 3 = acceptable, 4 = sufficient, 5 = inadequate). Physicians additionally rated medical correctness. Missing answers were ranked worst and not rated on Likert scales. Descriptive statistics were performed. Lower mean scores indicating superior performance. Questions were grouped into five clusters: disease understanding and diagnosis (Cluster A), disease course, organ involvement and prognosis (Cluster B), treatment, safety and monitoring (Cluster C), self-management, lifestyle and symptom control (Cluster D), and life impact, psychosocial aspects and family planning (Cluster E).
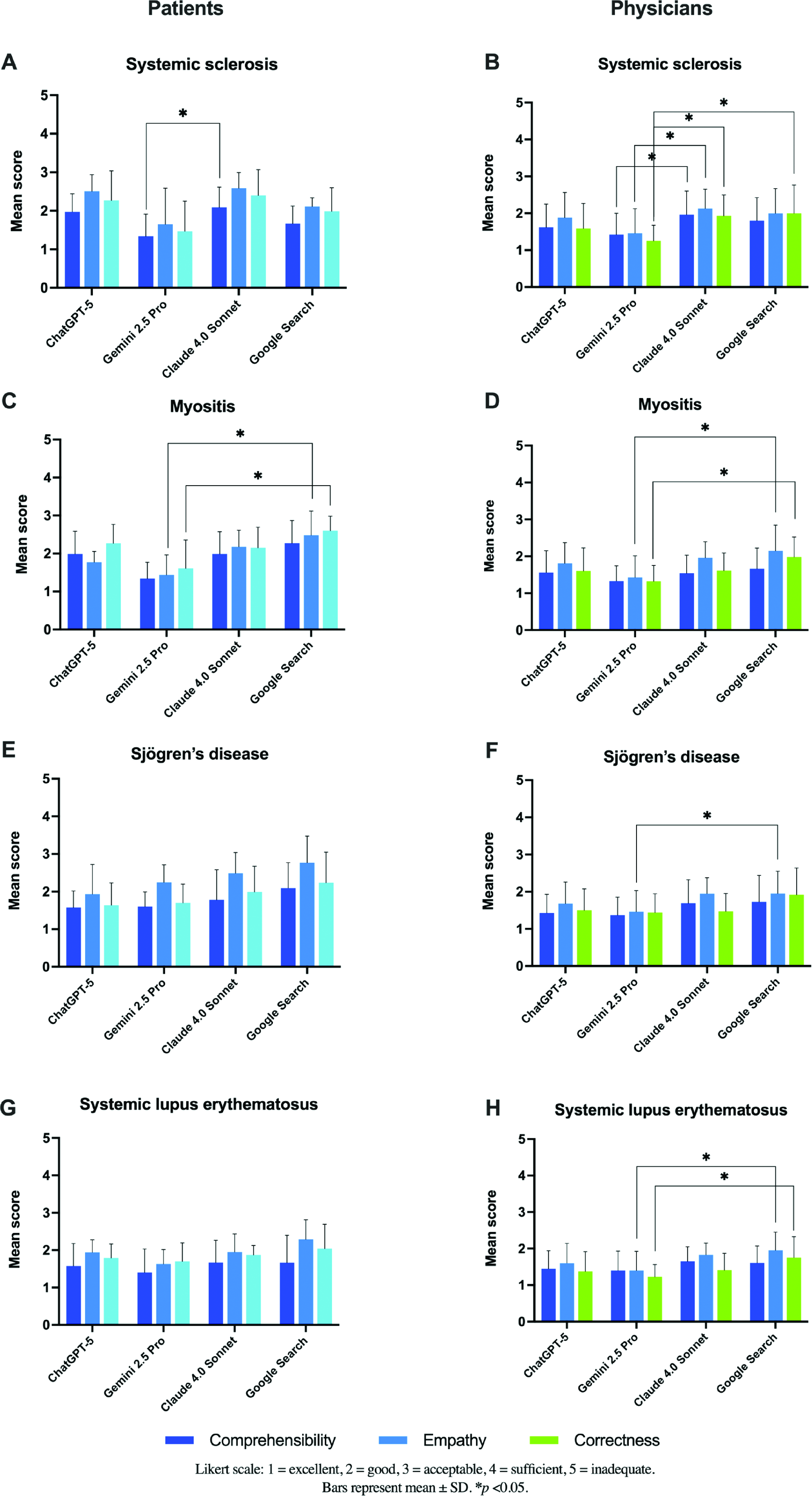
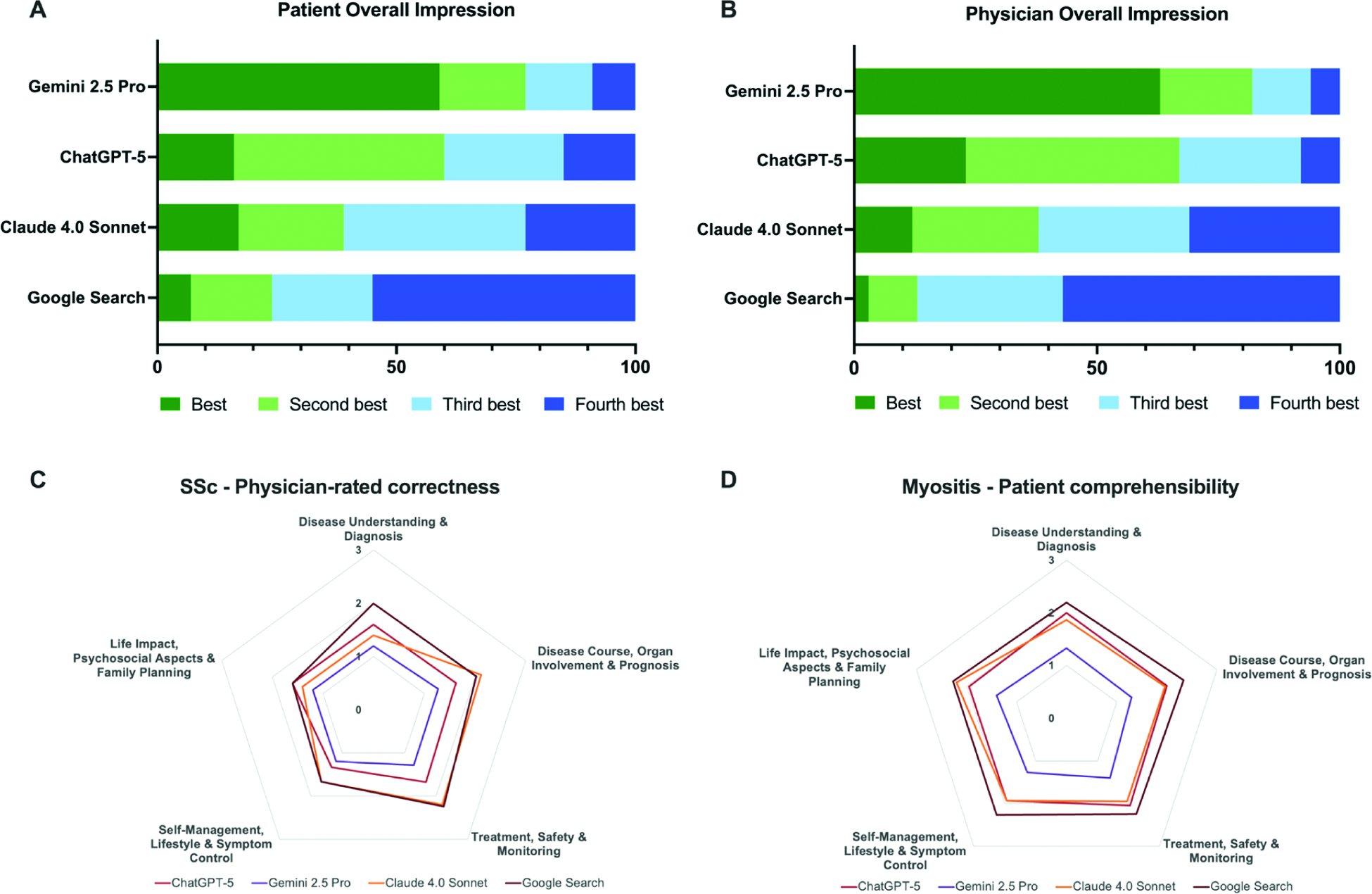
Results: Across all CTDs, both patients and rheumatologists rated LLM-generated responses favorably, with consistently good domain ratings for empathy, trustworthiness and comprehensibility (Figure 1). Besides this, physicians rated medical correctness as consistently accurate across models. Patient-rated between-model differences were small and largely restricted to IIM (Gemini 2.5 Pro vs Google Search) and SSc (Gemini 2.5 Pro vs Claude 4.0 Sonnet), while no differences were observed in SLE and only overall rating differed in SjD (ChatGPT-5 vs Google Search). In physician ratings, significant between-model differences were detected across rated domains, predominantly involving Gemini 2.5 Pro—most often versus Google Search (Figure 1). Additionally, both patients and physicians most frequently ranked Gemini 2.5 Pro as the best overall option (rank 1: 59% and 63%, respectively), while Google Search was most often rated the worst overall (rank 4: 55% and 57%, respectively). (Figure 2A–B). Exploratory analyses across predefined question clusters revealed no consistent pattern, aside from isolated cluster-specific differences (Figure 2C–D).
Conclusions: Using a representative set of frequently asked disease-related questions from CTD patient advocacy groups, general-purpose LLMs generated responses that physicians consistently rated as medically accurate and patients rated as empathetic and easy to understand. Compared with the conventional Google Search, LLMs—particularly Gemini 2.5 Pro—achieved superior overall ratings across multiple patient-centered domains. While Google—Search-based information was largely medically correct, LLMs offered added value in terms of clarity and empathy. When implemented with appropriate safeguards and physician oversight, LLMs may meaningfully complement established patient education strategies in rheumatology.
Mean patient and physician rating scores for responses concerning four connective tissue diseases generated by ChatGPT-5, Gemini 2.5 Pro, Claude 4.0 Sonnet, and Google Search. For each disease, outputs were evaluated on four domains—comprehensibility (dark blue), empathy (blue), trustworthiness (light blue, patients) and correctness (green, physicians), using a 5-point Likert-type scale (higher scores indicate better ratings). Bars show mean scores and error bars indicate standard variability across ratings. Statistically significant pairwise differences between systems are indicated by brackets (p < 0.05). Panels: ( A ) Myositis, ( B ) Systemic sclerosis, ( C ) Sjögren disease, and ( D ) Systemic lupus erythematosus.
Preference rankings and domain-specific performance profiles of information generated by ChatGPT-5, Gemini 2.5 Pro, Claude 4.0 Sonnet, and Google Search. ( A ) Patient overall impression: stacked horizontal bars depict the proportion (%) of evaluations in which each system was ranked best (I), second best (II), third best (III), or fourth best (IV). (B ) Physician overall impression: analogous ranking distribution by physicians. ( C ) Systemic sclerosis (SSc)—physician-rated correctness: radar plot of mean likert scores across five content clusters, with larger polygons indicating lower correctness. ( D ) Myositis-patient-rated comprehensibility: radar plot of mean likert scores across the same five domains, with larger polygons indicating lower comprehensibility; 1 = excellent, 2 = good, 3 = acceptable.
Funding: This study was financially supported by Abbvie.
Acknowledgments: NIL.
Disclosure of Interests: None declared.