fetching data ... 
Background: Effective management of rheumatoid arthritis (RA) relies heavily on sustained patient education to support treatment adherence, risk awareness, and long-term self-management. In routine clinical practice, however, time constraints frequently limit the depth and consistency of counselling that rheumatologists can provide.
Increasingly, patients seek health information from Large Language Models (LLMs), using them as informal “digital health assistants” for disease education and decision-making. While these systems offer on-demand responses, there are concerns regarding factual inaccuracies and unsafe recommendations.
Although prior studies have evaluated the general medical accuracy of LLMs, there is a paucity of rheumatology-focused evaluations that systematically assess safety, actionability, and clinical reliability across common patient scenarios.
This study aimed to conduct a blinded, head-to-head evaluation of five leading LLMs (ChatGPT, Claude, Deepseek, Gemini, Grok), assessing their ability to generate accurate, safe, and actionable responses to frequently asked RA patient questions, as judged by practising rheumatologists.
To perform a blinded, head-to-head comparison of five large language models in responding to frequently asked rheumatoid arthritis patient questions spanning diagnosis, treatment, and long-term management.
To evaluate the factual accuracy, completeness, safety and harm avoidance, readability and clarity, and actionability of AI-generated responses using a multi-reviewer rheumatologist assessment framework.
To explore inter-model variability and identify domains and question types where AI-generated content may be suitable for supervised patient education.
Methods: A set of 15 questions, which are clinically relevant and patient-facing were developed, spanning symptoms, diagnosis, treatment, disease monitoring, medication safety and lifestyle considerations. All models were posed with the same questions without specific settings (zero shot prompting), generating a total of 75 unique AI responses (15 questions × 5 models).
Each response was independently assessed by three blinded expert reviewers using a predefined evaluation framework. Reviewers were unaware of the originating model for each response. Content was rated on a 5-point Likert scale across five domains.
Responses were anonymised and randomised prior to evaluation to minimise recognition and order bias. Reviewers completed assessments independently, without discussion or consensus scoring, ensuring unbiased domain-level evaluation.
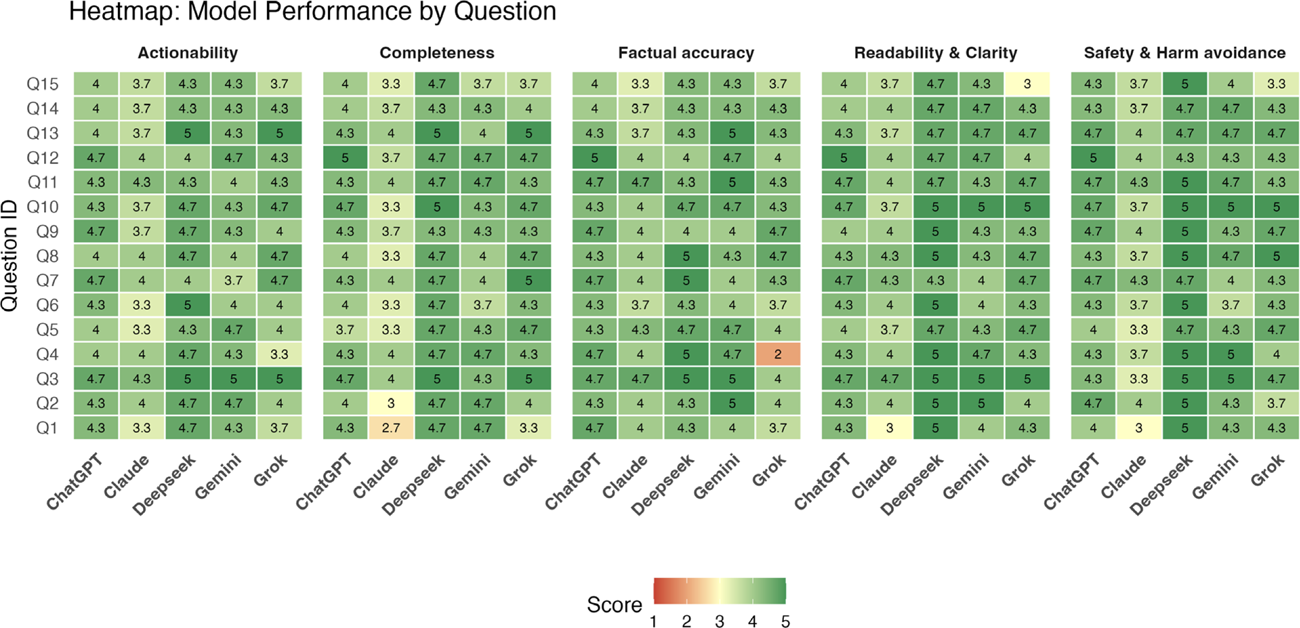
Domain-wise scores were aggregated across reviewers and models. Comparative performance between LLMs was analysed descriptively and visually using heat map to highlight inter-model differences across evaluation domains.
Results: A total of 1,125 individual domain ratings were analysed (15 questions × 5 models × 3 reviewers × 5 domains). Reviewer agreement was high, with 91.8% of ratings within ±1 point. Conventional IRR metrics (ICC=0.19) were limited by score clustering at the upper end (ceiling effect).
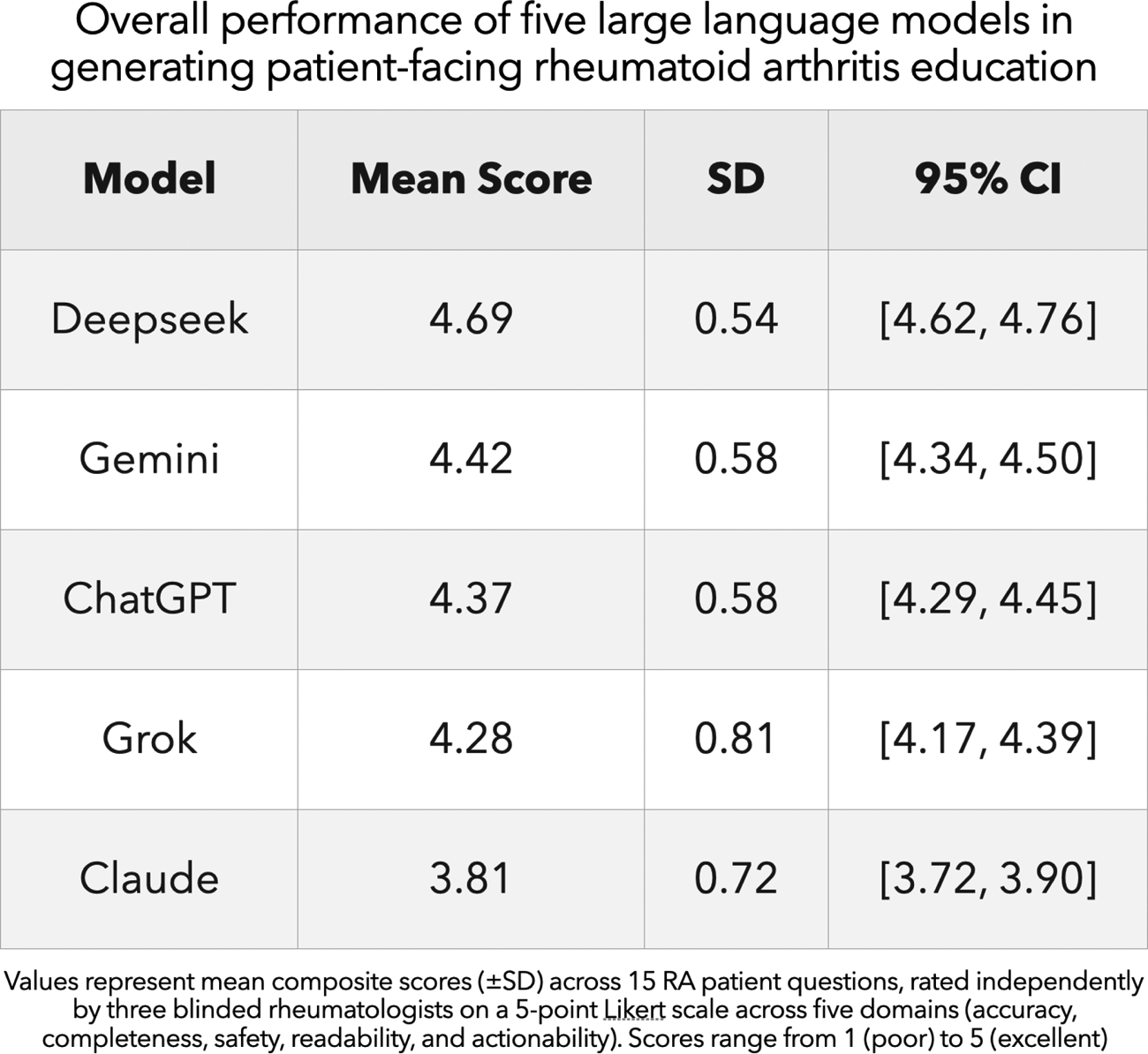
Deepseek demonstrated the highest overall performance (mean score 4.69, SD 0.54; 95% CI 4.62–4.76), consistently achieving near-excellent ratings across all evaluated domains. Its strongest differentiation was observed in Actionability, where responses provided structured, practical guidance for complex patient concerns such as fatigue management.
Gemini (mean 4.42, SD 0.58; 95% CI 4.34–4.50) and ChatGPT (mean 4.37, SD 0.58; 95% CI 4.29–4.45) formed a closely matched second tier, demonstrating high factual accuracy and safety, though with slightly less depth and contextual framing compared to the top-performing model.
Grok achieved moderate performance (mean 4.28, SD 0.81), characterised by greater variability across domains, particularly in completeness and clarity.
Claude performed significantly lower than peer models (mean 3.81, SD 0.72; 95% CI 3.72–3.90), most notably in Completeness, where explanations of diagnostic concepts occasionally lacked sufficient depth for newly diagnosed patients.
Domain-Specific Findings
- Safety & Harm Avoidance : All models performed well, with mean safety scores exceeding 4.0 and no clearly dangerous or inappropriate medical recommendations identified.
- Actionability : This domain most strongly differentiated models. Higher-performing systems translated information into practical coping strategies and next steps, whereas lower-performing models tended to provide descriptive but non-directive responses.
- Emotional and Psychosocial Content : Questions addressing anger, fatigue, and cognitive symptoms (“brain fog”) were handled with unexpectedly high empathy and clarity by the top three models, suggesting potential utility in addressing the psychological burden of RA alongside biomedical education.
Conclusions: Not all large language models are equivalent in their capacity to support medical education. This blinded, head-to-head evaluation demonstrates that selected high-performing models—particularly Deepseek, Gemini, and ChatGPT—have reached a level of practical clinical utility in rheumatoid arthritis patient education, delivering responses that are accurate, safe, and consistently actionable.
The strongest models performed well both in biomedical accuracy and addressing fatigue, emotional distress, and cognitive concerns—domains that are central to patient experience but frequently under-addressed in time-constrained clinical encounters.
While human oversight and clinician judgment remain indispensable, these findings suggest that validated LLMs may be responsibly integrated as educational extenders—supporting the creation of high-quality patient materials and enhancing health literacy outside the consultation room. Future professional guidance should move beyond broad cautions regarding AI use and instead focus on model-specific evaluation, validation, and recommendation for patient-facing applications.
Table 1.
REFERENCES: NIL.
Acknowledgments: NIL.
Disclosure of Interests: Sree Hari Reddy Gadekallu The author received speaker honoraria from pharmaceutical companies outside the submitted work. No funding was received for the present study., B G Dharmanand The author received speaker honoraria from pharmaceutical companies outside the submitted work. No funding was received for the present study., Sarath CM Veeravalli The author received speaker honoraria from pharmaceutical companies outside the submitted work. No funding was received for the present study., Srikantiah Chandrashekara The author received speaker honoraria from pharmaceutical companies outside the submitted work. No funding was received for the present study., Haipeng Liu: None declared, Thippa Reddy Gadekallu: None declared.