fetching data ... 
Background: Early diagnosis and tight control of rheumatoid arthritis (RA) are essential to prevent irreversible joint damage. Current monitoring methods mostly depend on subjective clinical examinations, creating a critical need for objective, quantifiable metrics. We have previously presented the automated recognition of dorsal finger folds of proximal interphalangeal joints (PIP) on hand photographs as potential digital biomarkers for joint swelling.
Objectives: For a better assessment of disease activity, we investigated the feasibility of using digital image analysis of metacarpophalangeal (MCP) joint photographs to infer joint swelling. We aimed to determine whether computer vision algorithms could distinguish between swollen and non-swollen joints using images collected in a routine clinical setting.
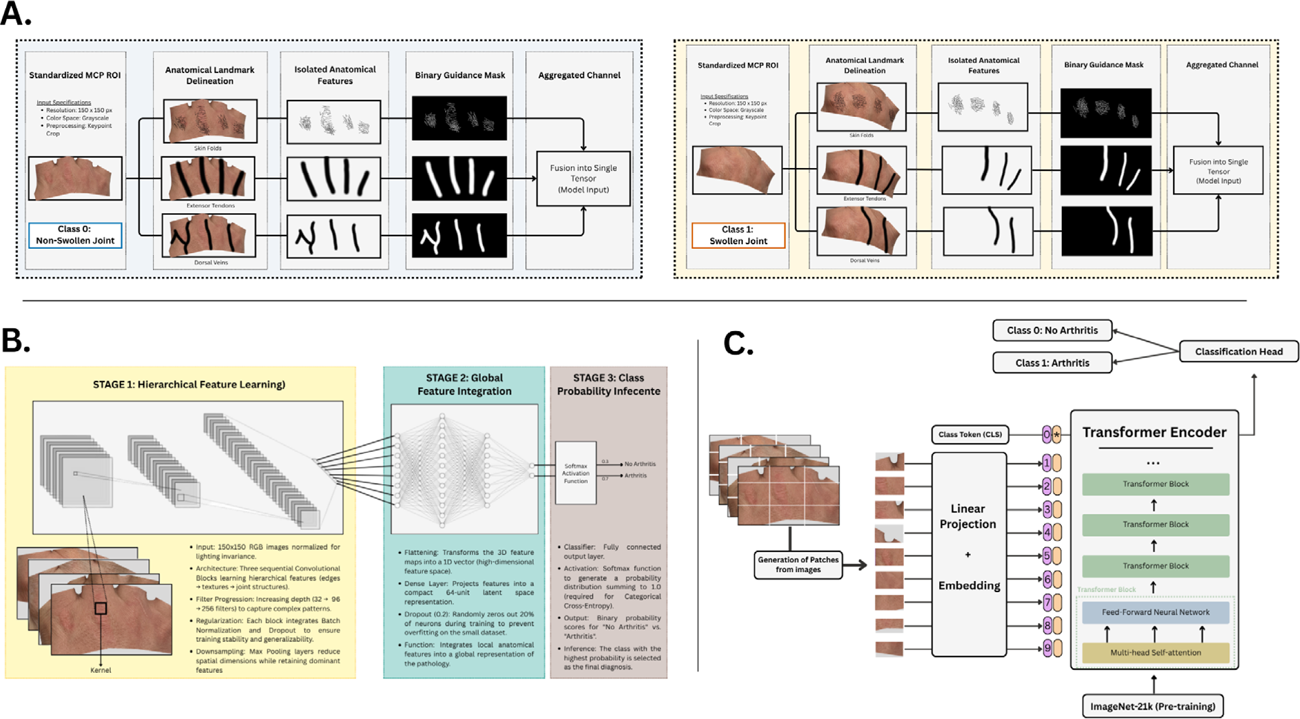
Methods: A total of 1,157 hand images were collected from RA patients during routine consultations using standard smartphone cameras under non-direct lighting. Images were processed using automatic keypoint detection to isolate MCP joints and labeled by a rheumatologist into two categories (swollen vs non-swollen). We trained and validated six supervised learning models. Classical ML: Logistic Regression, Random Forest, and Support Vector Machine (SVM) using Principal Component Analysis (PCA) and class-weighting strategies. Deep Learning (DL): a standard CNN, a Multi-Input CNN incorporating manual anatomical annotations (masks of dorsal skin folds, extensor tendons, and the dorsal venous) to test if human guidance improves learning, a Vision Transformer (ViT) pre-trained on ImageNet-21k, fine-tuned via Transfer Learning. Performance was evaluated on an independent test set using Area Under the Receiver Operating Characteristic Curve (AUC-ROC), confusion matrix, and accuracy.
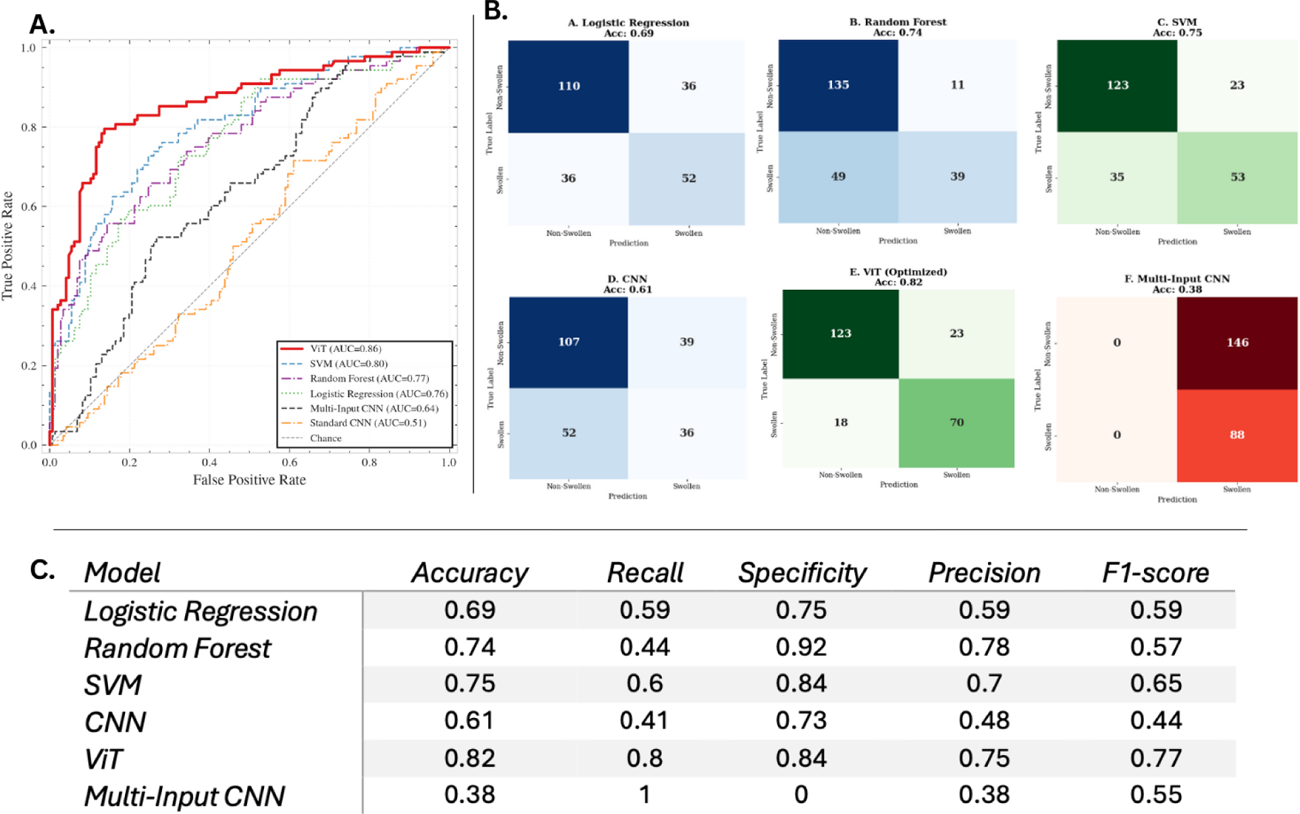
Results: The ViT-based transfer learning model demonstrated superior performance, achieving an AUC-ROC of 0.87 and the highest sensitivity for detecting pathology (Recall 0.74), effectively using global attention mechanisms to capture structural joint changes. In comparative analysis, the ViT significantly surpassed the best-performing classical baseline (SVM, AUC 0.80), with a confirmed statistical significance (p=0.02). The Multi-Input CNN taking into account manual anatomic annotations, either alone (tendons, veins) or as a combined model, showed limited performance (AUC 0.64).
Conclusions: Transfer learning with a ViT emerged as most effective strategy to infer MCP joint swelling on standard smartphone photographs. Autonomous feature discovery of this model was superior to multi-input of anatomic features.
Architectural overview of the Deep Learning models. (A ) Pipeline for the Multi-Input CNN, illustrating the manual anatomical annotation process where masks of dorsal skin folds, extensor tendons, and the dorsal venous were generated to guide the analysis. (B ) Standard CNN architecture relying on hierarchical feature learning. (C ) The Vision Transformer (ViT) architecture, which splits images into patches and uses a Transformer Encoder with multi-head self-attention (pre-trained on ImageNet-21k) to infer the presence of swollen joints
Performance evaluation. (A ) Receiver Operating Characteristic (ROC) curves showing the Vision Transformer (ViT) achieving the highest discriminative power (AUC=0.87), followed by the Support Vector Machine (SVM, AUC=0.80). (B ) Confusion matrices comparing classification patterns. Note the balanced profile of the ViT and SVM, contrasting with the limited performance of the Multi-Input CNN despite anatomical guidance. (C ) Tabular summary of performance metrics. The ViT achieves the best clinical balance with an F1-score of 0.77 and a Sensitivity (Recall) of 0.80. Note that the Multi-Input CNN displays a misleading Sensitivity of 1.0 (100%) due to its failure to identify any healthy cases (Specificity 0).
REFERENCES: NIL.
Acknowledgments: NIL.
Disclosure of Interests: Asier García-Alija: None declared, Lorenzo Russo: None declared, Marc Blanchard: None declared, Jules Maglione: None declared, Cinja Nadana Koller: None declared, Thomas Hügle Abbvie, GSK, BMS, Novartis, Lilly, Werfen, Fresenius Kabi, Atreon, Vtuls.